publications
Publications by categories in reversed chronological order.
2026
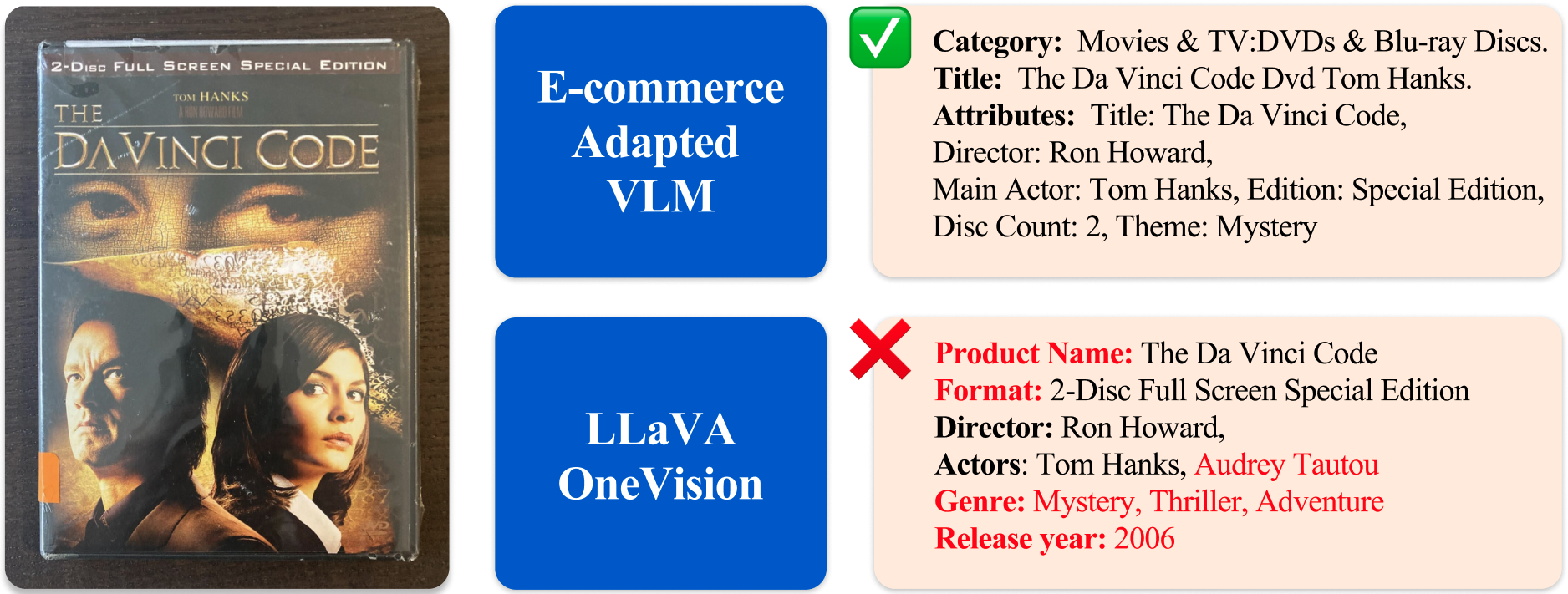
- Adapting Vision-Language Models for E-commerce Understanding at ScaleMatteo Nulli, Orshulevich Vladimir, Tala Bazazo, Christian Herold, Michael Kozielski, Marcin Mazur, Szymon Tuzel, Cees G. M. Snoek, Seyyed Hadi Hashemi, Omar Javed, Yannick Versley, and Shahram KhadiviIn Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 5: Industry Track) , Mar 2026Oral
E-commerce product understanding demands by nature, strong multimodal comprehension from text, images, and structured attributes. General-purpose Vision–Language Models (VLMs) enable generalizable multimodal latent modeling, yet there is no documented, well-known strategy for adapting them to the attribute-centric, multi-image, and noisy nature of e-commerce data, without sacrificing general performance. In this work, we show through a large-scale experimental study, how targeted adaptation of general VLMs can substantially improve e-commerce performance while preserving broad multimodal capabilities. Furthermore, we propose a novel extensive evaluation suite covering deep product understanding, strict instruction following, and dynamic attribute extraction.
@inproceedings{nulli-etal-2026-adapting, title = {Adapting Vision-Language Models for {E}-commerce Understanding at Scale}, author = {Nulli, Matteo and Vladimir, Orshulevich and Bazazo, Tala and Herold, Christian and Kozielski, Michael and Mazur, Marcin and Tuzel, Szymon and Snoek, Cees G. M. and Hashemi, Seyyed Hadi and Javed, Omar and Versley, Yannick and Khadivi, Shahram}, editor = {Matusevych, Yevgen and Eryi{\u{g}}it, G{\"u}l{\c{s}}en and Aletras, Nikolaos}, booktitle = {Proceedings of the 19th Conference of the {E}uropean Chapter of the {A}ssociation for {C}omputational {L}inguistics (Volume 5: Industry Track)}, month = mar, year = {2026}, address = {Rabat, Morocco}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2026.eacl-industry.38/}, doi = {10.18653/v1/2026.eacl-industry.38}, pages = {496--512}, isbn = {979-8-89176-384-5}, note = {Oral}, hugging_face_page = {https://huggingface.co/papers/2602.11733}, } - Meeting SLOs, Slashing Hours: Automated Enterprise LLM Optimization with OptiKITNicholas Santavas, Kareem Eissa, Patrycja Cieplicka, Piotr Florek, Matteo Nulli, Stefan Vasilev, Seyyed Hadi Hashemi, Antonios Gasteratos, and Shahram KhadiviIn MLSys 2026 Industry Track , Mar 2026
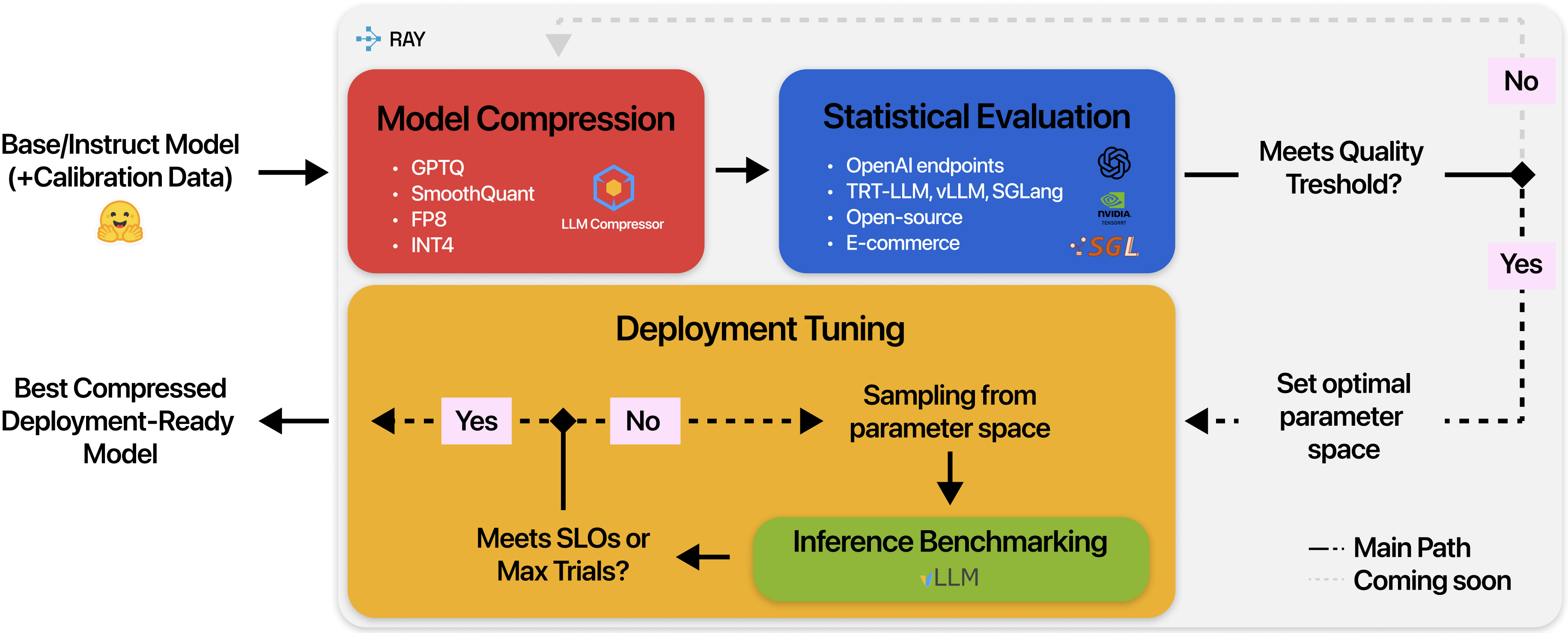
Enterprise LLM deployment faces a critical scalability challenge: organizations must optimize models systematically to scale AI initiatives within constrained compute budgets, yet the specialized expertise required for manual optimization remains a niche and scarce skillset. This challenge is particularly evident in managing GPU utilization across heterogeneous infrastructure while enabling teams with diverse workloads and limited LLM optimization experience to deploy models efficiently. We present OptiKIT, a distributed LLM optimization framework that democratizes model compression and tuning by automating complex optimization workflows for non-expert teams. OptiKIT provides dynamic resource allocation, staged pipeline execution with automatic cleanup, and seamless enterprise integration. In production, it delivers more than 2x GPU throughput improvement while empowering application teams to achieve consistent performance improvements without deep LLM optimization expertise. We share both the platform design and key engineering insights into resource allocation algorithms, pipeline orchestration, and integration patterns that enable large-scale, production-grade democratization of model optimization. Finally, we open-source the system to enable external contributions and broader reproducibility.
@inproceedings{santavas2026meetingslosslashinghours, title = {Meeting SLOs, Slashing Hours: Automated Enterprise LLM Optimization with OptiKIT}, author = {Santavas, Nicholas and Eissa, Kareem and Cieplicka, Patrycja and Florek, Piotr and Nulli, Matteo and Vasilev, Stefan and Hashemi, Seyyed Hadi and Gasteratos, Antonios and Khadivi, Shahram}, year = {2026}, eprint = {2601.20408}, archiveprefix = {arXiv}, primaryclass = {cs.DC}, url = {https://arxiv.org/abs/2601.20408}, booktitle = {MLSys 2026 Industry Track} }
2025
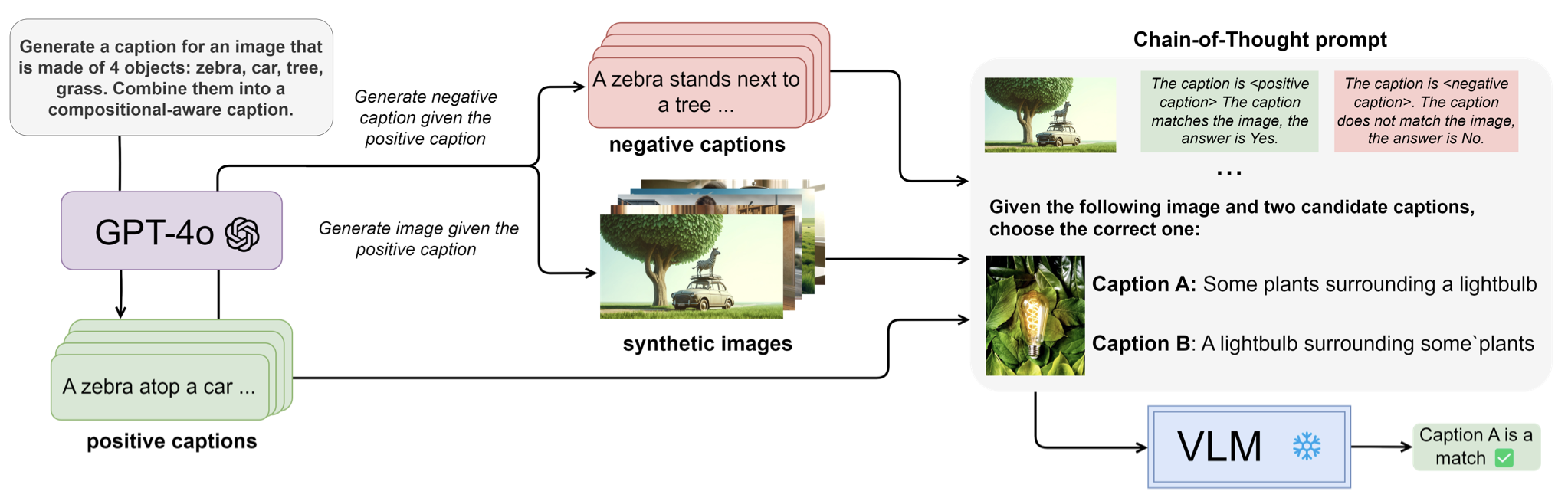
- Object-Guided Visual Tokens: Eliciting Compositional Reasoning in Multimodal Language ModelsIn EurIPS 2025 Workshop on Principles of Generative Modeling (PriGM) , Mar 2025
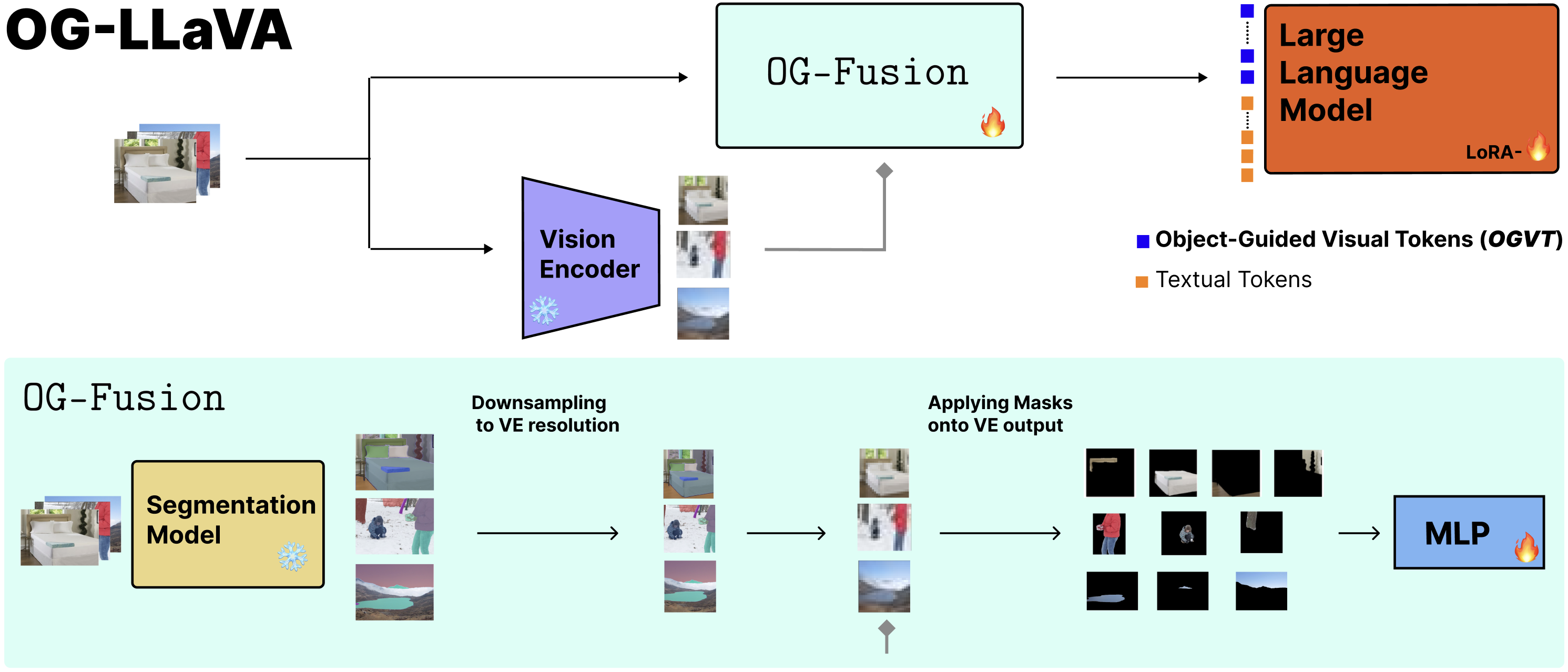
Multimodal Large Language Models (MLLMs) employ contrastive pre-trained Vision Encoders whose performance falls short in compositional understanding and visual reasoning. This is mostly due to their pre-training objective aimed at retrieval between similar images or captions rather than an in-depth understanding of all components of an image. Moreover, while state-of-the-art image encoding methods yield strong performance, they inflate the number of visual input tokens by roughly two to three times, thereby significantly lengthening both training and inference times. To alleviate these issues, we present OG-LLaVA (Object-Guided LLaVA), a novel multimodal architecture which, through an innovative connector design OG-Fusion, enhances the model’s ability to understand and reason about visual content without substantially increasing the number of tokens or unfreezing the Vision Encoder. A core element of OG-Fusion is the combination of CLIP representations with segmentations. By leveraging the descriptive power of advanced segmentation models, OG-LLaVA attains superior performance at tasks that require a deeper understanding of object relationships and spatial arrangements, within the domains of compositional reasoning and visual grounding. The code is available at https://github.com/MatteoNulli/og_llava/tree/main.
@inproceedings{nulli2025objectguided, title = {Object-Guided Visual Tokens: Eliciting Compositional Reasoning in Multimodal Language Models}, author = {Nulli, Matteo and Najdenkoska, Ivona and Derakhshani, Mohammad Mahdi and Asano, Yuki M}, booktitle = {EurIPS 2025 Workshop on Principles of Generative Modeling (PriGM)}, year = {2025}, url = {https://openreview.net/forum?id=yvY1T3hHEQ}, }
2024
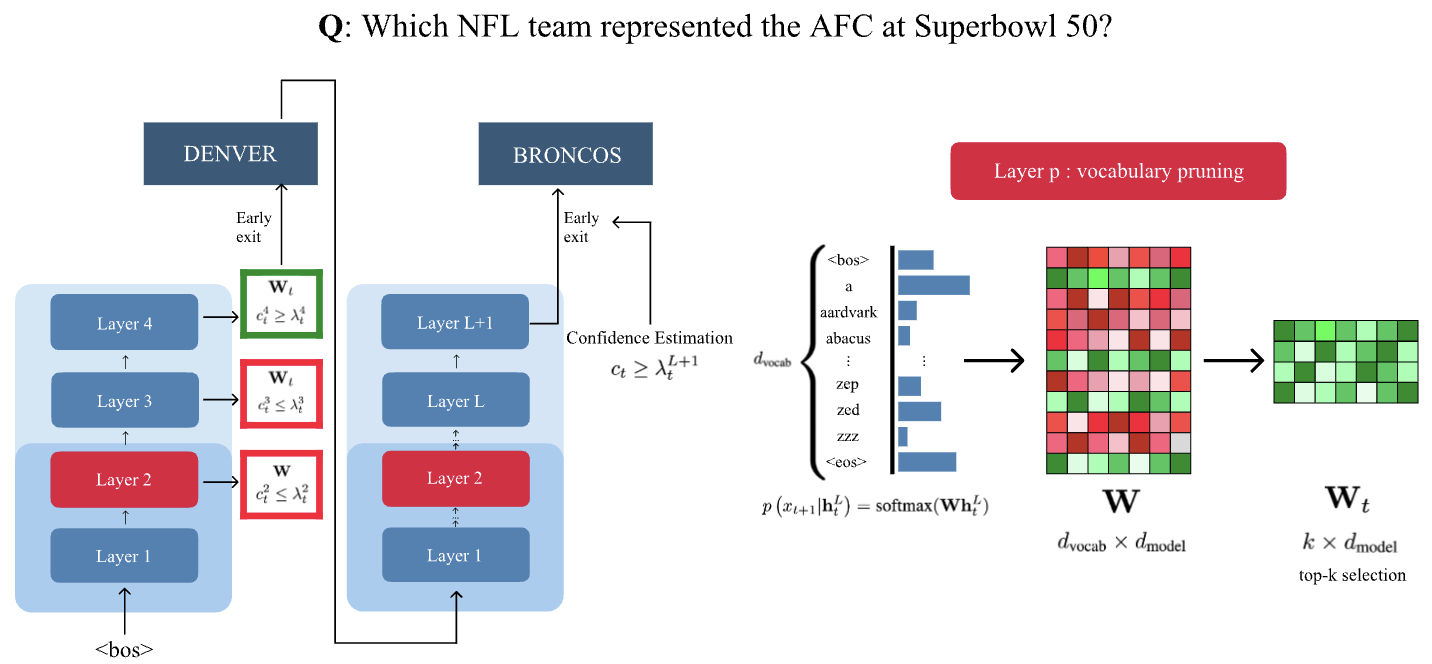
- Dynamic Vocabulary Pruning in Early-Exit LLMsNeurIPS Efficient Natural Language and Speech Processing, Mar 2024
Increasing the size of large language models (LLMs) has been shown to lead to better performance. However, this comes at the cost of slower and more expensive inference. Early-exiting is a promising approach for improving the efficiency of LLM inference by enabling next token prediction at intermediate layers. Yet, the large vocabulary size in modern LLMs makes the confidence estimation required for exit decisions computationally expensive, diminishing the efficiency gains. To address this, we propose dynamically pruning the vocabulary at test time for each token. Specifically, the vocabulary is pruned at one of the initial layers, and the smaller vocabulary is then used throughout the rest of the forward pass. Our experiments demonstrate that such post-hoc dynamic vocabulary pruning improves the efficiency of confidence estimation in early-exit LLMs while maintaining competitive performance.
@article{vincenti2024dynamic, title = {Dynamic Vocabulary Pruning in Early-Exit LLMs}, author = {Vincenti*, Jort and Sadek*, Karim Abdel and Velja*, Joan and Nulli*, Matteo and Jazbec, Metod}, year = {2024}, eprint = {2410.18952}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, journal = {NeurIPS Efficient Natural Language and Speech Processing}, url = {https://arxiv.org/abs/2410.18952}, } - In-Context Learning Improves Compositional Understanding of Vision-Language ModelsMatteo Nulli, Anesa Ibrahimi, Avik Pal, Hoshe Lee, and Ivona NajdenkoskaIn ICML 2024 Workshop on Foundation Models in the Wild , Mar 2024
Vision-Language Models (VLMs) have shown remarkable capabilities in a large number of downstream tasks. Nonetheless, compositional image understanding remains a rather difficult task due to the object bias present in training data. In this work, we investigate the reasons for such a lack of capability by performing an extensive bench-marking of compositional understanding in VLMs. We compare contrastive models with generative ones and analyze their differences in architecture, pre-training data, and training tasks and losses. Furthermore, we leverage In-Context Learning (ICL) as a way to improve the ability of VLMs to perform more complex reasoning and understanding given an image. Our extensive experiments demonstrate that our proposed approach outperforms baseline models across multiple compositional understanding datasets.
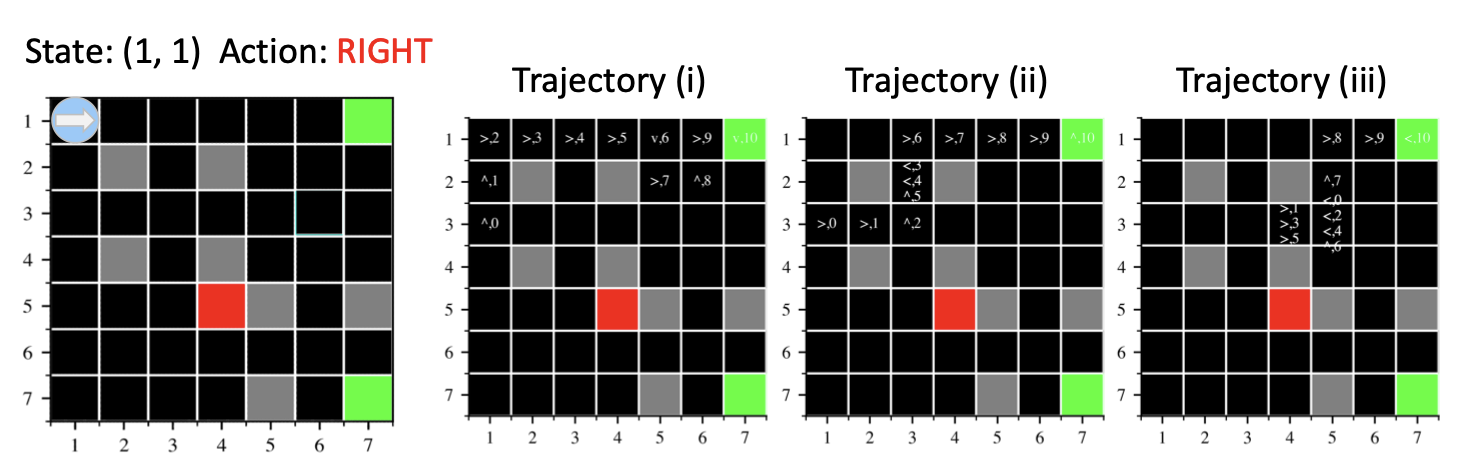
@inproceedings{nulli2024context, title = {In-Context Learning Improves Compositional Understanding of Vision-Language Models}, author = {Nulli, Matteo and Ibrahimi, Anesa and Pal, Avik and Lee, Hoshe and Najdenkoska, Ivona}, booktitle = {ICML 2024 Workshop on Foundation Models in the Wild}, year = {2024}, eprint = {2407.15487}, archiveprefix = {arXiv}, primaryclass = {cs.CV}, url = {https://arxiv.org/abs/2407.15487}, } - ’Explaining RL Decisions with Trajectories’: A Reproducibility StudyTransactions on Machine Learning Research, Mar 2024
This work investigates the reproducibility of the paper "Explaining RL decisions with trajectories“ by Deshmukh et al. (2023). The original paper introduces a novel approach in explainable reinforcement learning based on the attribution decisions of an agent to specific clusters of trajectories encountered during training. We verify the main claims from the paper, which state that (i) training on less trajectories induces a lower initial state value, (ii) trajectories in a cluster present similar high-level patterns, (iii) distant trajectories influence the decision of an agent, and (iv) humans correctly identify the attributed trajectories to the decision of the agent. We recover the environments used by the authors based on the partial original code they provided for one of the environments (Grid-World), and implemented the remaining from scratch (Seaquest and HalfCheetah, Breakout, Q*Bert). While we confirm that (i), (ii), and (iii) partially hold, we extend on the largely qualitative experiments from the authors by introducing a quantitative metric to further support (iii), and new experiments and visual results for (i). Moreover, we investigate the use of different clustering algorithms and encoder architectures to further support (ii). We could not support (iv), given the limited extent of the original experiments. We conclude that, while some of the claims can be supported, further investigations and experiments could be of interest. We recognize the novelty of the work from the authors and hope that our work paves the way for clearer and more transparent approaches.
@article{sadek2024explaining, title = {'Explaining {RL} Decisions with Trajectories{\textquoteright}: A Reproducibility Study}, author = {Sadek*, Karim Abdel and Nulli*, Matteo and Velja*, Joan and Vincenti*, Jort}, journal = {Transactions on Machine Learning Research}, issn = {2835-8856}, year = {2024}, url = {https://arxiv.org/abs/2411.07200}, }