Accepted to EurIPS, Workshop on Principles of Generative Modelling
Motivation
Matteo Nulli going through Figure 1 at the ELLIS Honours Presentation (left), Matteo Nulli presenting the paper at EurIPS (right)
Most Multimodal Large Language Models (MLLMs) (2, 3, 4, 5, 6) use contrastively pre-trained vision encoders (7). They work well on many tasks, but often struggle when it comes to compositional understanding and reasoning on understanding interndependencies between objetcs, as highlighted in 8 and 9. That’s because these encoders are mainly trained for image–caption retrieval, not for truly breaking down and understanding all parts of a scene. Another issue is efficiency: state-of-the-art vision encoders generate 2–3x more visual tokens (Any-Resolution in 6 and Spatial Visual Aggregator in 5), which slow down both training and inference.
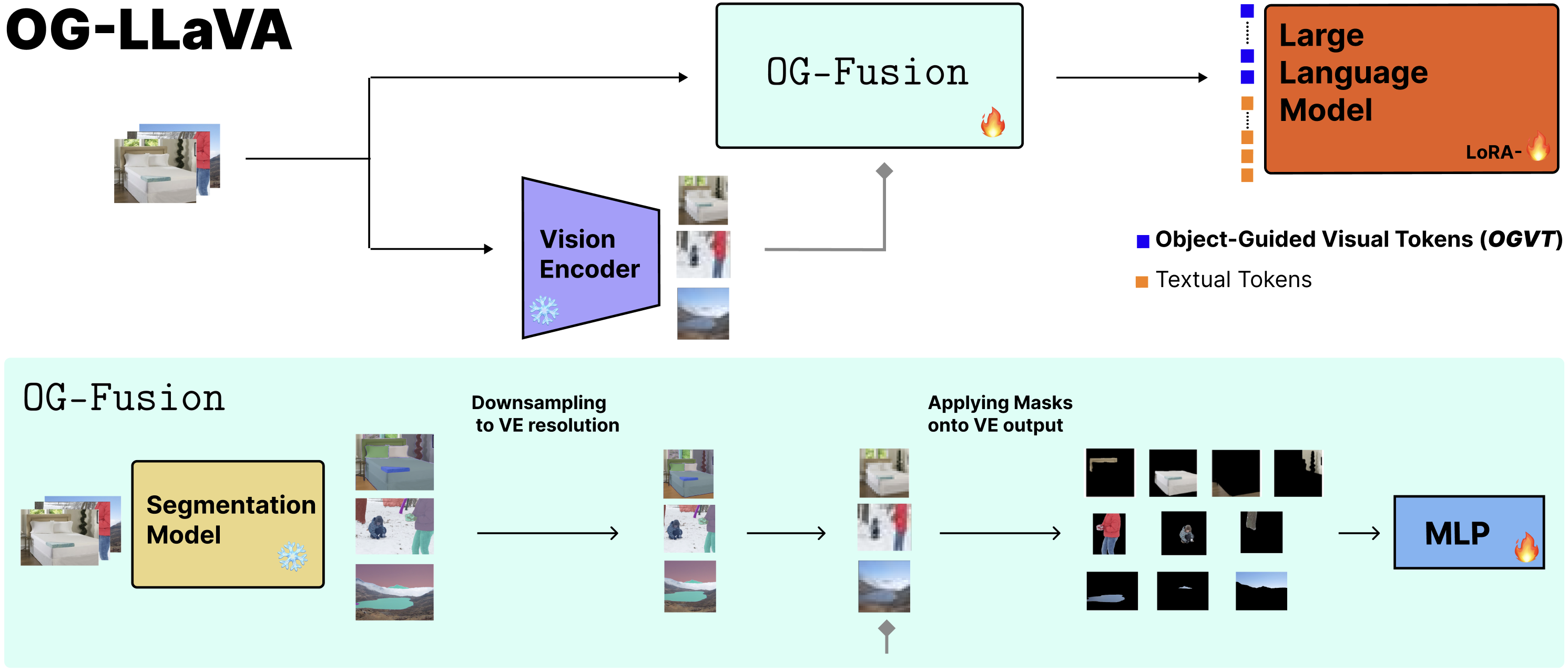
To tackle these problems, we introduce OG-LLaVA (Object-Guided LLaVA). With our new connector design, OG-Fusion, the model can reason about visual content more effectively—without adding lots of extra tokens or fine-tuning the vision encoder itself. At the core of OG-Fusion is a simple but powerful idea: combine CLIP representations with segmentation masks. This lets OG-LLaVA leverage the descriptive strength of segmentation models (10) to better capture object relationships and spatial arrangements. The result? OG-LLaVA outperforms comparable models on tasks demanding deep visual reasoning and grounding, while staying efficient.
Figure 1: OG-LLaVA architecture with OG-Fusion internal proces
Methodology
Given a single input image $\mathbf{X} \in \mathbb{R}^{C \times H \times W}$, we denote by $\mathbf{M} = {\mathbf{m}_i \mid i = 1,\dots,N} \subset \mathbb{R}^{H \times W}$ the corresponding set of $N$ binary segmentation masks, where each mask satisfies $\mathbf{m}_i \in {0,1}^{H \times W}$. Our objective is to construct a set of segmentation-aware visual tokens, such that each variable-length token segment is explicitly associated with one object mask.
For clarity, we describe the procedure assuming a batch size of one; a fully rigorous mathematical formulation is deferred to the Appendix of the paper (see Section Object-Guided Visual Tokens).
Masks and Features Extraction
We begin by extracting object-level structure from each image through a segmentation model, which produces a set of binary masks $\mathbf{M}$. During training, visual features are obtained from a Vision Encoder, yielding representations $\mathbf{X’} \in \mathbb{R}^{V \times F}$. These features are aligned with the corresponding segmentation masks and processed through an ad-hoc downsampling operator designed to preserve object-centric information.
Downsampling Operator
We define a downsampling operator $\Phi_{\alpha}$ that maps a high-resolution binary mask to a lower-resolution representation. Each output bin aggregates neighboring pixels and is marked as foreground if it contains at least $\alpha$ foreground pixels. Applying this operator independently to all $N$ masks results in a set of downsampled binary masks:
Further implementation details of $\Phi_{\alpha}$ are provided in Appendix A of the paper.
Object-Guided Visual Tokens
Following preprocessing, the downsampled masks $\mathbf{M}’$ are applied to the visual feature matrix $\mathbf{X}’$ through an index-based row-selection matrix $P_i$. This operation extracts object-specific visual fragments:
The resulting fragments are then projected into the language-model embedding space via a Multi-Layer Perceptron (MLP), producing Object-Guided Visual Tokens (OGVT):
Here, $T$ denotes the total number of object-bearing bins retained after downsampling. While $T$ varies per image, its expected value remains close to the original token count ($T \approx V$). When multiple masks overlap on the same ViT bin, that bin is duplicated across different $\mathbf{Y}_i$. Due to mask thresholding and the use of rotary positional embeddings (RoPE), these duplicated tokens yield distinct projections and therefore do not collapse into identical attention keys. As a result, attention is naturally biased toward regions with higher object density, effectively reintroducing spatial grounding that is otherwise weakened in standard Transformer architectures. A formal analysis of token duplication effects is provided in Appendix B of the paper.
Model Architecture, Training, and Inference
To preserve architectural compatibility with LLaVA-1.5, we adopt CLIP ViT-L/14@336 (7) as the vision encoder. While CLIP is our primary choice, the proposed method is agnostic to the specific vision backbone.
We experiment with two large language models: Llama 3.1-8B-Instruct (11) and Llama 3.2-3B-Instruct (12), resulting in two variants OG-LLaVA-8B and OG-LLaVA-3B, respectively. An overview of the full OG-Fusion pipeline is shown in Figure 1. The architecture integrates a frozen Segment Anything Model 2 (SAM2) (10) backbone, followed by the object-guided token construction described above and a two-hidden-layer MLP with GeLU activations.
Training follows the visual instruction tuning paradigm of 13 and proceeds in two stages: (i) Vision–Language Alignment, where only OG-Fusion is unfrozen (ii) Supervised Fine-Tuning, where both the LLM and OG-Fusion are trained using LoRA (14).
The OGVT are then given as input to a Large Language Model together with Textual Tokens to produce an output. The ❄️ (snowflake) and 🔥 (fire) symbols in Figure 1 represent modules whose parameters are kept frozen or trained. LoRA emphasizes that not all parameters of the LLM are unfrozen, only the LoRA layers.
Although OGVTs are constructed using segmentation masks during training, the model can be evaluated both with and without mask infusion—demonstrating robustness by preserving the semantic structure of the original visual features $\mathbf{X}’$.
Results
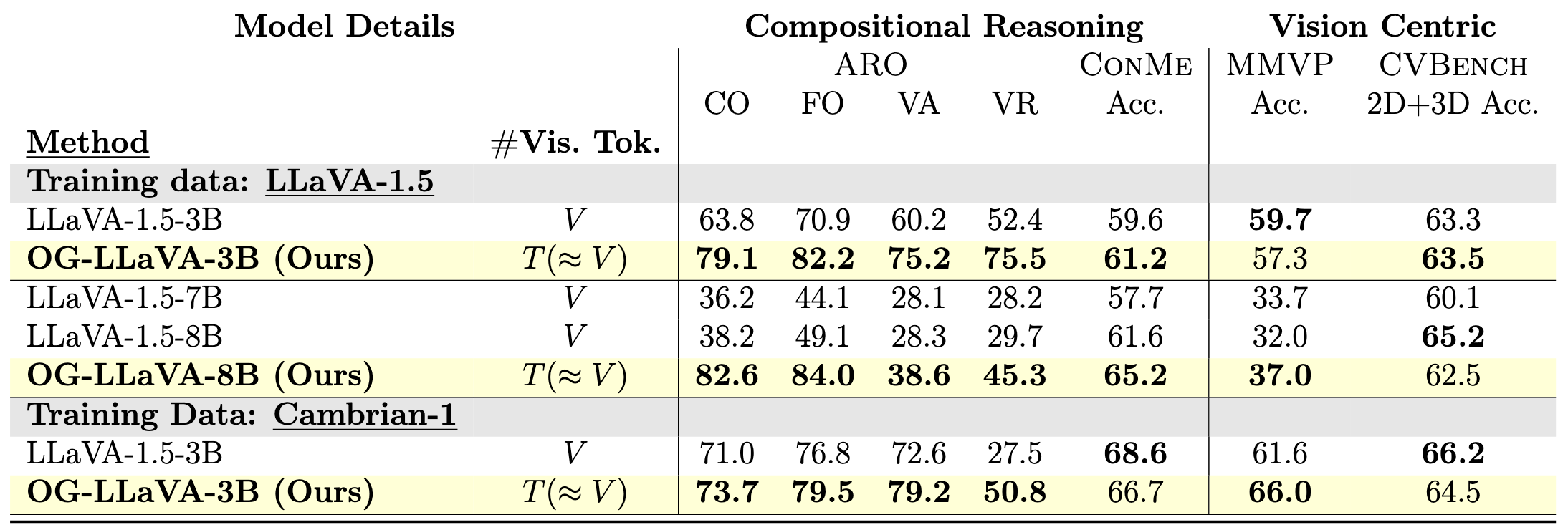
Our results on compositional reasoning and vision-centric benchmarks Table 1, show that OG-LLaVA consistently outperforms its baselines, across both LLaVA-1.5 and Cambrian-1 training setups. The improvements are not marginal—they’re large and systematic.
Compositional understanding
ARO:
+21% on Coco-Order (38.2 → 82.6) and +16% on Flickr-Order (49.1 → 84.0).
Visual Genome Attribution on average +10% across backbones and on Visual Genome Relation +20% across training data and model sizes.
ConME: steady +2% gains, peaking at 65.2 in the 8B setting (+3.6 over the strongest baseline).
Vision-centric reasoning
MMVP: about +3 points on average (e.g. 32.0 → 37.0 in 8B, 61.6 → 66.0 with Cambrian-1 data).
CVBench: stable performance, with only ±1 point fluctuations.
Table 1: OG-LLaVA performance on Compositional Reasoning and Vision Centric tasks compared with LLaVA baselines.
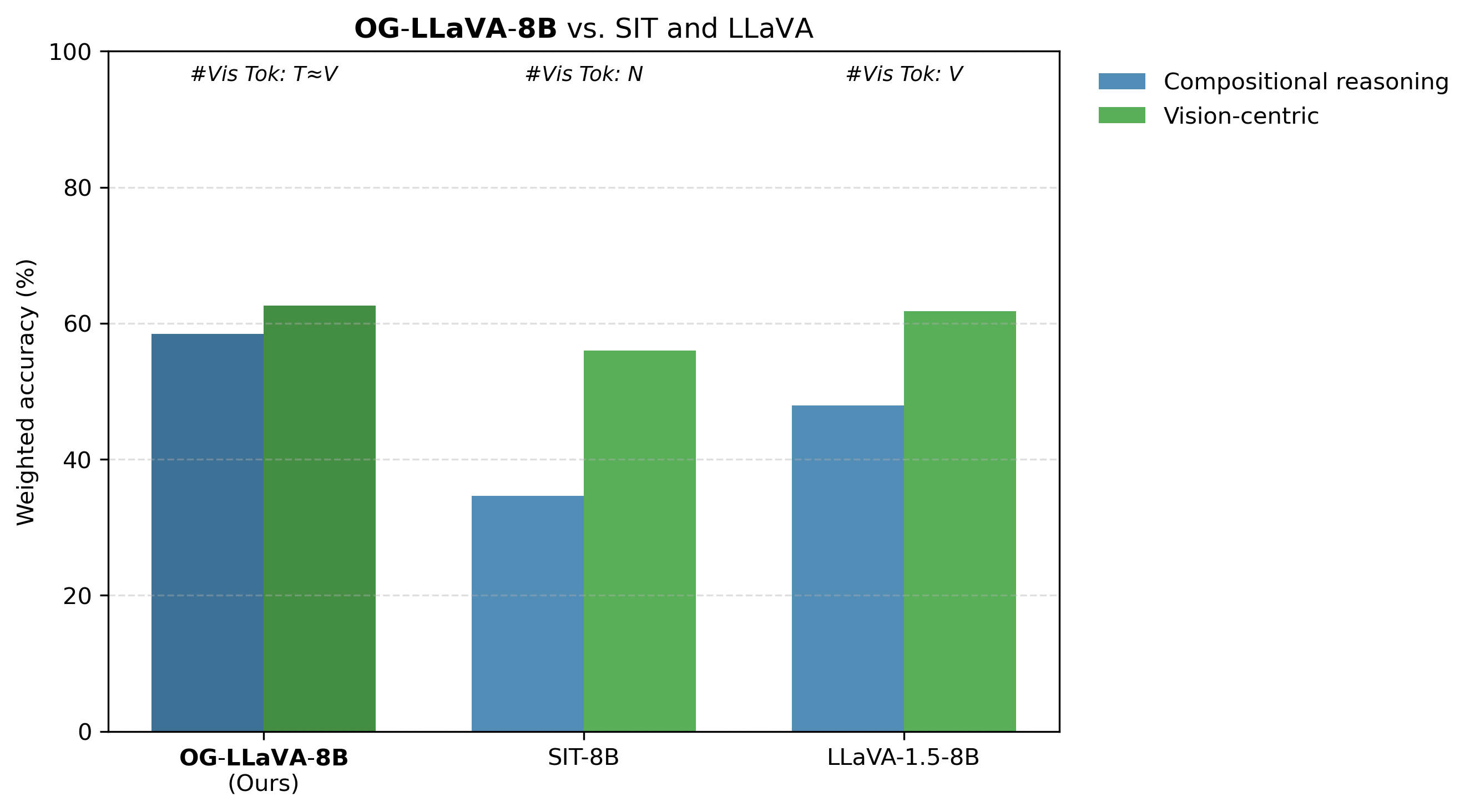
In Figure 7, we compare OG-LLaVA-8B with SIT-8B, and LLaVA-1.5-8B under the same backbone. SIT-8B stands for Subobject-level Image Tokenization (SIT) a new study employing a comparable segmentation-infusion method. The results are clear: OG-LLaVA consistently outperforms SIT, with more than a 25% advantage on compositional reasoning and a 10% edge in visual grounding.
There’s also a key difference in usability. OG-LLaVA works flexibly both with and without segmentation masks at inference, while SIT requires pre-computed masks every time. This not only adds non-trivial overhead—since a separate segmentation model must run first—but also makes the system less adaptable. In practice, the reduced token count doesn’t outweigh the complexity introduced, whereas OG-LLaVA preserves efficiency without imposing such constraints.
Figure 7: OG-LLaVA vs Subobject Level Image Tokenization and LLaVA-1.5 on Compositional Reasoning and Vision Centric tasks.
Qualitative Results
Figure 2: OG-LLaVA vs LLaVA-1.5 on Compositional Reasoning Benchmark ConMe.
Figure 3: OG-LLaVA vs LLaVA-1.5 on Vision Grounding benchmark MMVP.
The images we picked cover all kinds of tricky challenges—spotting tiny details, telling apart subtle colors, reading depth cues, recognizing materials, making sense of spatial layouts, and even detecting small objects. They’re designed to push visual–language reasoning to its limits. What’s key is that these examples are tested at inference time with no extra fine-tuning, so any boost (or drop) in performance comes purely from the Object-Guided priors built into OG-LLaVA.
In Figure 4, 5 and 6 we highlight a range of cases where OG-LLaVA consistently demonstrates sharper perception and more grounded reasoning, from subtle posture cues to tricky color judgments and material recognition.
Fine-grained human pose: correctly reads a batter’s stance, placing the bat up and behind instead of in front. (Figure 4 - Picture1)
Precise color & reflection reasoning: rules out red in umbrellas, confining it to apples/plate, while the baseline gets misled, as well as captures realistic color reflections on materials and disambiguates different hues. (Figure 4 - Picture2), (Figure 5 - Picture8) & (Figure 6 - Picture2)
Material recognition: identifies a skate-park surface as concrete, not asphalt and glass instead of curtains. (Figure 4 - Picture4) & (Figure 5 - Picture1)
Font recognition: picks up subtle font characteristics, showing solid OCR ability. (Figure 5 - Picture2)
Object counting & detection: counts giraffes correctly where the baseline stumbles and spots a distant coffee maker amid clutter, avoiding confusion with a blender. (Figure 5 - Picture4) & (Figure 6 - Picture3)
Fashion understanding: distinguishes between short sleeves and cap sleeves. (Figure 5 - Picture7)
Dynamic cues: understands a distant sail is inflated with strong breeze, matching the surfing context. (Figure 6 - Picture1)
Shape recognition: correctly identifies train tracks in the background. (Figure 6 - Picture4)
Together, these examples underline how OG-LLaVA moves beyond surface-level cues. It pays attention to fine details, adapts across diverse tasks, and reasons about entire scenes in a way that more closely reflects human understanding.
Figure 4: OG-LLaVA vs LLaVA-1.5 on ConMe Replace-Relation examples.
Figure 5: OG-LLaVA vs LLaVA-1.5 on ConMe Replace-Object examples.
Figure 6: OG-LLaVA vs LLaVA-1.5 on ConMe Replace-Relation examples.
Citation
If you use this work, please cite:
@inproceedings{nulli2025objectguided,
title={Object-Guided Visual Tokens: Eliciting Compositional Reasoning in Multimodal Language Models},
author={Matteo Nulli and Ivona Najdenkoska and Mohammad Mahdi Derakhshani and Yuki M Asano},
booktitle={EurIPS 2025 Workshop on Principles of Generative Modeling (PriGM)},
year={2025},
url={https://openreview.net/forum?id=yvY1T3hHEQ}
}