Perception, Localization, Planning and Control on RAE Robots
R. den Braber, M. Nulli*, D. Zegveld
Intelligent Robotics Lab, University of Amsterdam
*Equal Contribution
Introduction
In this blogpost we go over our process of building an integrated perception–localization–planning–control pipeline on the RAE robot. Below we go over Camera Calibration and Line Following, Localization and Curlying Match playing (see Video 1) and Mapping, Planning and Control, to allow our RAE Robot to freely move across our environment.
Camera Calibration and Line Following
In this section we demonstrate the effectiveness of our line-following pipeline by using a RAE robot to move parallel to the lines spanned by ceiling lights.
We began with camera calibration, which is shown to reduce distortion resulting in improved navigation accuracy. We do so comparing two algorithms of differing complexity, ultimately using Zhang’s [1] camera calibration technique.
Thereafter we developed a line‑following algorithm.
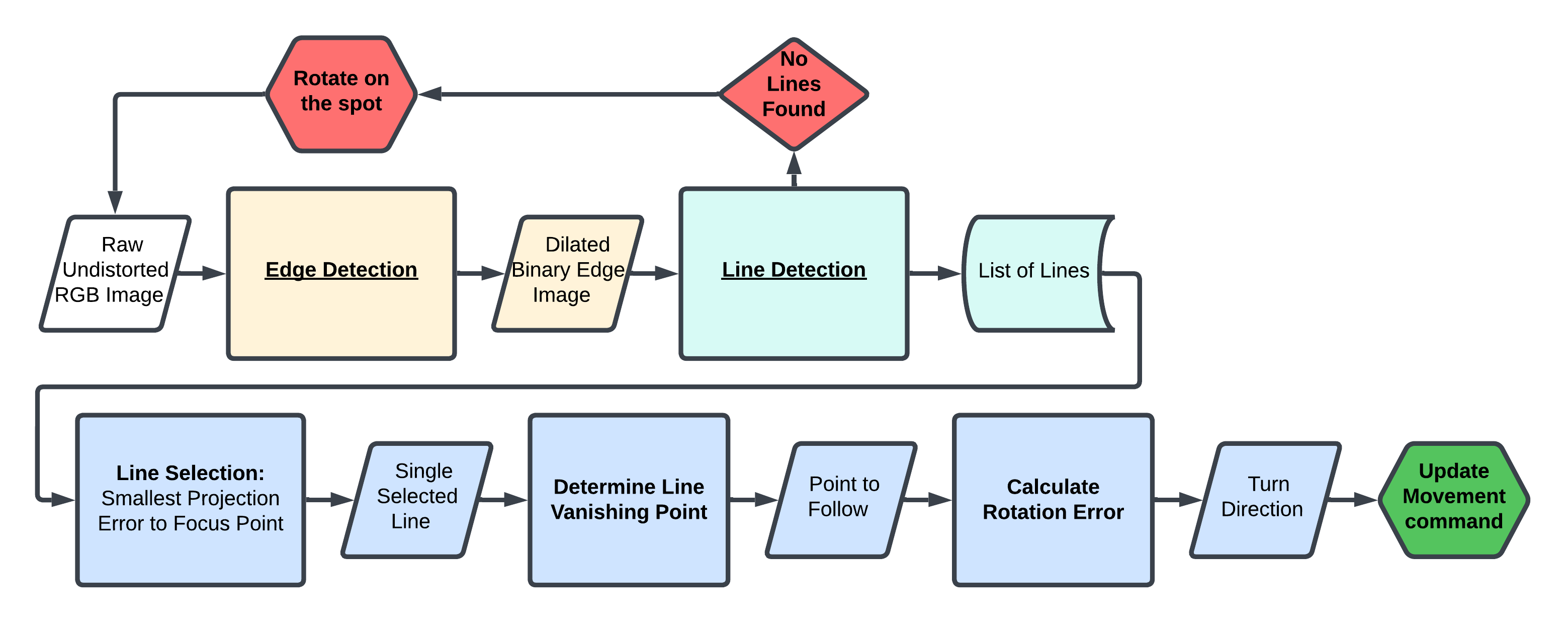
First step is edege detection through an optimized version of the Canny edge detection algorithm. The next step is line detection, whose aim is to return a list of all lines that are spanned by the ceiling lights. It leverages a fine-tuned version of the Hough transform in addition to our triangular region of interest see blue line in Figure 2. Both the edge and line detection stages are refined by tuning the parameters and by adding additional steps such as image dilation to make the ceiling lines more prominent in the resulting image. This increases the robustness of our algorithm so that it can properly detect lines in difficult conditions, for example, at different angles, lighting conditions, and deal with gaps between the ceiling lights.

Lastly, the line-following algorithm implements a way to consistently select the closest line, which removes the distraction of multiple detected lines. Next, using the selected line, we calculate a vanishing point to move towards instead of blindly following the line as this proves to increase navigational consistency and accuracy see Figure 2. Additionally, in an ablation study we found that utilizing this vanishing point approach allows our robot to still perform well, even without camera calibration, with only a slight potential reduction in navigational accuracy. This robustness highlights the strengths and adaptability of our pipeline (see Figure 1) which results in a stable and accurate ceiling light line following algorithm for the RAE robot.
Localization and Curlying Match
In this chapter we go over our setup for localization and curling match playing with the RAE robot, see Figure 3.
We start by performing marker detection on QR-style code markers from APRILTAG. After improving our marker detection algorithm, we localize ourselves in real-world coordinates using the center of the field as the (0, 0) point. We consider different distance measurements and locate ourselves based on two, three, or more markers. Our marker-based localization algorithm allows us to obtain an average localization error of less than 13 cm, see Figure 4.
We utilize an Extended Kalman Filter [2] to merge our marker-based localization with the odometry motor-based estimated position to achieve a more accurate and robust location estimate during the match, see Figure 3.

Lastly, we design an algorithm which combines (Figure 5. ) a feature-based and position-based solution to ensure accurate and robust localization during the curling match. Furthermore, we incorporate object avoidance to navigate around other RAE robots that may block the path to the target location. Our algorithm achieves effective results through the coordination of three key nodes:
- Localization node: Estimates the robot’s position using the detected markers.
- Driving node: Uses motor-based odometry to estimate the robot’s position and combines it with marker-based localization in order to navigate toward the target location.
- Object avoidance node: Signals when an object is in the way and identifies where in the image this object is to ensure that it is avoided (see the next section for more details).
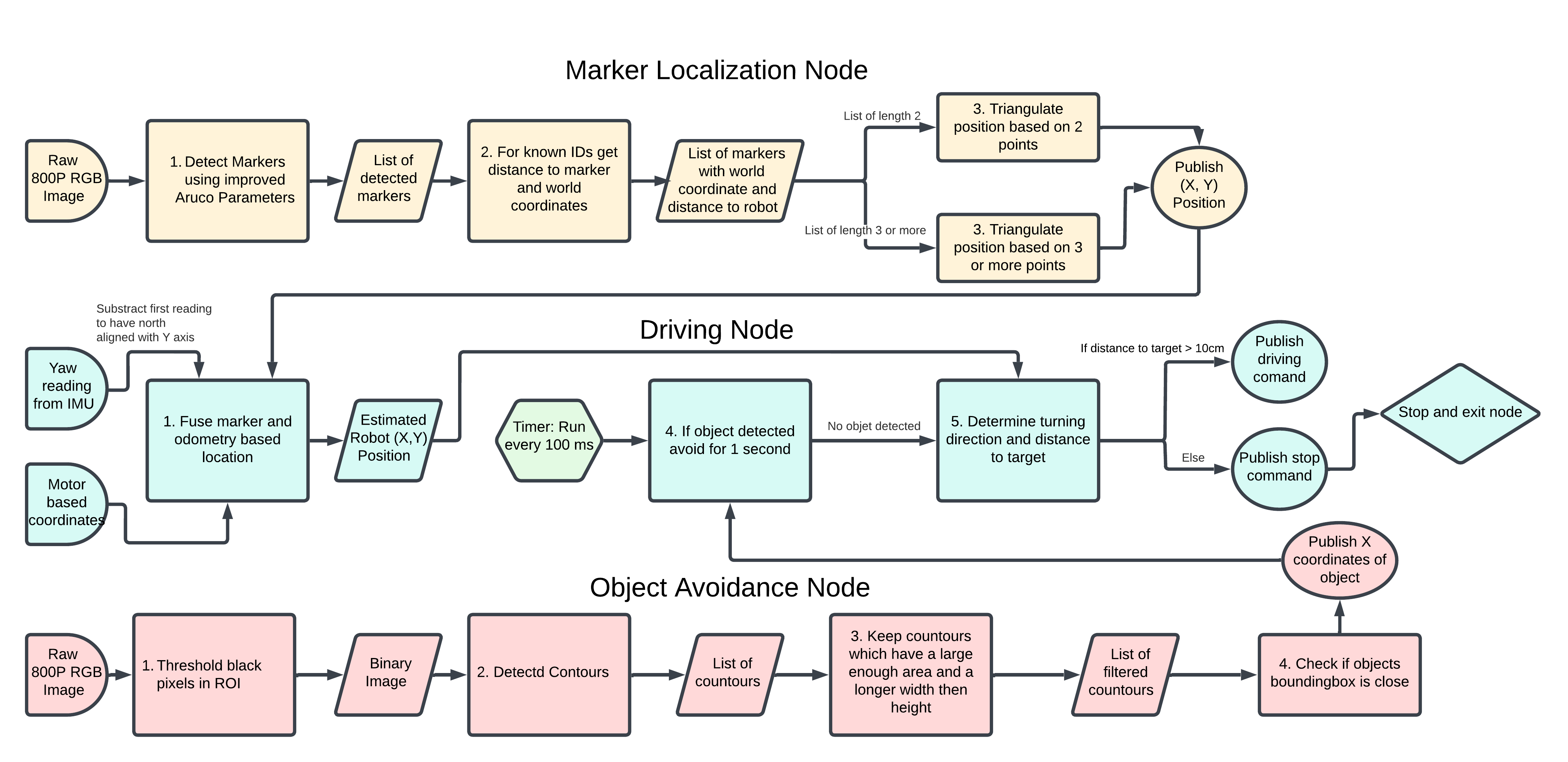
The visual marked-based localization works as described above and publishes the current location estimate of the robot as a point on a ROS topic. The driving node picks up this topic and combines it with its motor-based odometry using an EKF. For the driving node, we implemented the motor-based odometry by hand as we ran into some curious issues when trying to center the robot’s position using the built-in odometry implementation. This built-in implementation used an EKF as well between the motor-based odometry and the Inertial Measurement Unit (IMU), but upon resetting the starting location of the robot to (0,0) the IMU would behave erratically and report weird headings with a large error from the actual heading. For our implementation, we make use of the heading (yaw) reported by the IMU. However, before every run, we automatically reset the heading to 0 (north) by reading the initial IMU yaw value and subtracting this value from all further IMU readings. Now we can rely on the reported fixed headings, we also need to localize in cases where no visual localization is provided due to not detecting markers. We do this by subscribing to the motor odometry topic. This topic publishes the robot’s location as (x,y) coordinates from its internal reference frame based on the motor odometry. However, we want the (x,y) position in our real-world coordinate frame. To obtain this we calculate the distance that the robot drives by calculating the Euclidean distance between two (x,y) coordinate points from the last 2 consecutive motor odometry messages. We then use our heading theta to calculate the robot’s (x,y) position in our real-world coordinate frame using
x += \cos(\theta) \cdot (distance \ driven) and y += \sin(\theta) \cdot (distance \ driven)
Since we now have both the motor-based odometry location and the marker-based visual location, we combine these two with an EKF to create a more accurate, reliable, and robust prediction of our robot’s real-world location. This process, partially outlined in Section 2.5, is further clarified below. For both the odometry- and marker-based locations we use a different uncertainty matrix. For the marker location, we use an uncertainty matrix with a 13 cm standard deviation, this value corresponds to the average marker-based localization error that we found over a wide range of field positions, with different numbers of markers detected at different distances. The uncertainty matrix for the motor-based odometry uses a standard deviation of 20 cm, expressing the average error we measured after driving to different target locations relying solely on the motor odometry.
Given the reliable prediction of our world location and our known (improved) heading readings, we now have the information to navigate toward the real-world coordinates of the target location. We achieve this by calculating the required heading to drive from our current estimated location to the target location. Then we calculate the smallest angle between the current heading and the required heading and determine the direction in which to turn our robot by looking at the sign of this resulting angle. Furthermore, the rotation speed is determined by scaling this angle (in radians) with a gain factor, resulting in slower turns for smaller corrections. Lastly, the forward driving speed is calculated based on the distance to the target location, with a capped maximum speed limit. This similarly to the angle case, ensures more precise movements as the robot approaches the target location.
With the full pipeline active, the robot is able to drive towards all 5 target locations reliably, and can accurately localize itself from any starting position on the field using the detected markers, see Table 1.

Mapping, Planning and Control
Finally we report the process of mapping and finding a path through a maze using only the video stream as captured with the RGB camera off the RAE robot.
First we create a 3D point cloud is created through Structure from Motion (SfM) and optimize it with COLMAP [3], see Figure 6.

Thereafter, we filter the point cloud through a quantiles-based filtering method (Figure 7). This filtered cloud is converted into a topology mapping using approximate cell decomposition (Figure 8).

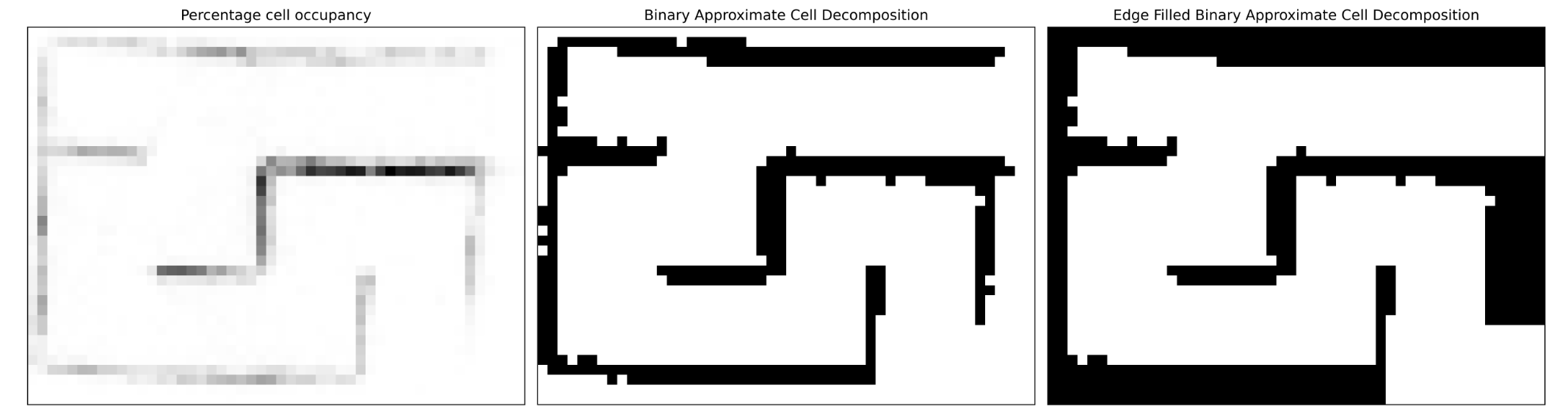
This topology mapping is then used to plan a path from the start to the end of the maze using Dijkstra’s algorithm. We first use vanilla Dijkstra, soon realizing the infeasibility of the algorithm with edges weighted by one, see Figure 9.
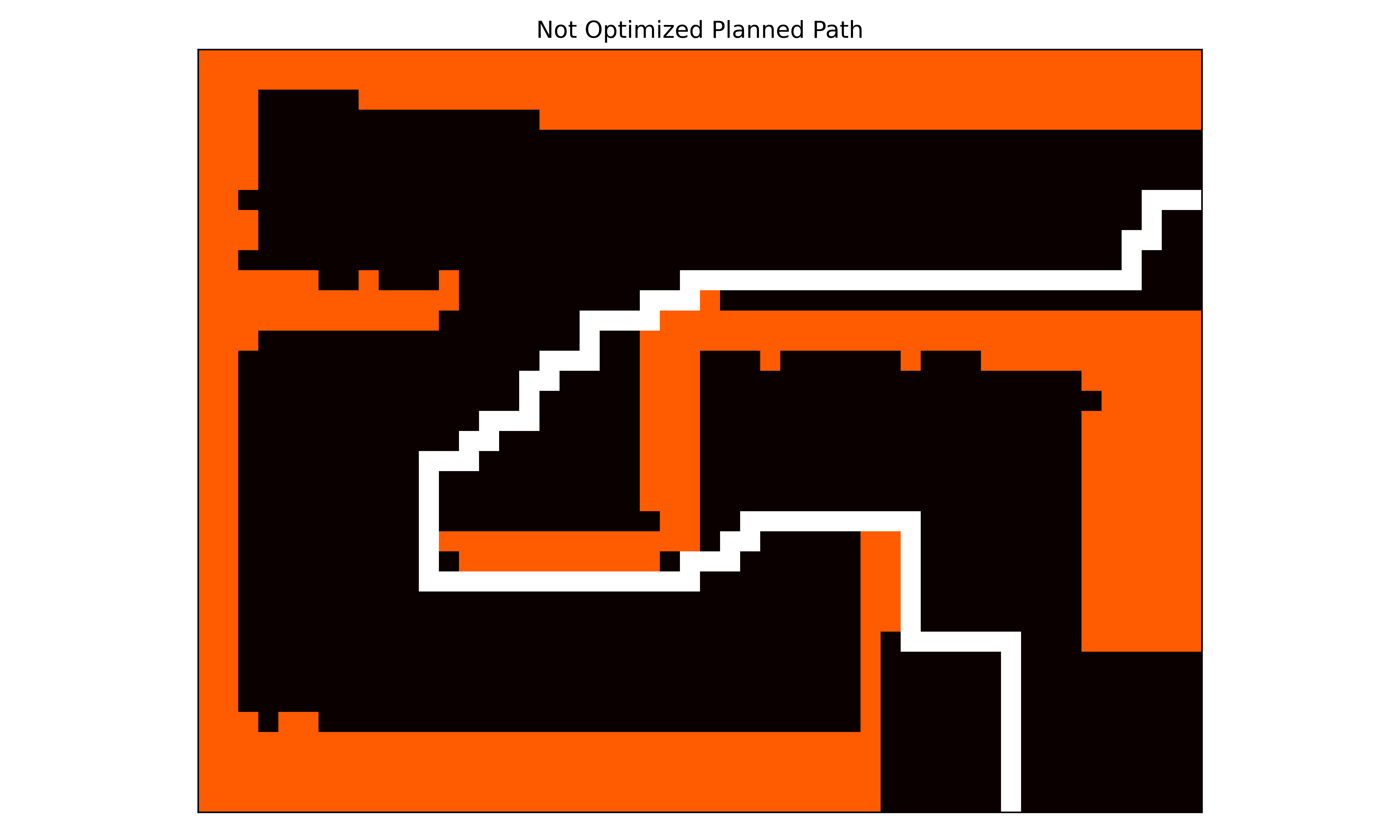
We thus focused on improving the route found using the default Dijkstra a lgorithm by changing it so that we prioritize movement along the center of the roads spanned by the maze. To this effect, we devised a different way to compute the cost for each edge. Instead of setting the cost to one, we added a distance to the occupied cells penalty. This distance penalty should be high if an edge is close to a wall and low if it is far away.
We used scipy.ndimage.distance\_transform\_edt to calculate for each free cell the shortest distance to each occupied cell and scale this by a factor of a hundred. However, adding this distance to each edge would give the opposite effect, as free cells in the middle have a larger distance to occupied cells. We could invert the distance by multiplying it by minus one. However, as Dijkstra tries to find the route with the lowest cost, this leads to negative loops and no solution. Therefore, instead, we took the cell with the largest distance and added this to the distance multiplied by minus one. This resulted in the cell with the largest distance to a free cell not having a penalty and cells close to the wall having the most significant penalty. As our graph is directed, we added the penalty of the outgoing node to each of its edges. For example, if we have the graph A → B. Edge → would get a cost of 1+ penalty(A). The path found using this cost function can be found in Figure 10 (left); this figure clearly shows that the new route follows the middle of the maze, making it considerably easier, more robust, and safer for a robot to follow. Additionally, Figure 10 (right) shows the computed penalty map, showing that our method works since cells in the middle of the path have a low penalty (white) and cells closer to the walls have an increasingly higher penalty (red).

Citation
If you use this work, please cite:
@misc{denbraber2025cvar,
author = {den Braber, R., and Nulli, M., and Zegveld, D.},
title = {Perception, Localization, Planning and Control on RAE Robots},
howpublished = {https://matteonulli.github.io/blog/2025/cvar/},
year = {2025},
}
Enjoy Reading This Article?
Here are some more articles you might like to read next: