Optimizing Predictions: Vocabulary Reduction and Contrastive Decoding in LLMs
K.A. Abdel Sadek *, M. Nulli *, J. Velja *, J. Vincenti *, G. Desimini
University of Amsterdam, UvA-Bosch Delta Lab, Krueger AI Safety Lab (KASL)
📄 Paper | 📝 Blogpost | 🧑💻 Code
Accepted to NeurIPS, Efficient Natural Language and Speech Processing
*Equal Contribution
Introduction

Recent advancements in Large Language Models (LLMs) have significantly improved performance across various Natural Language Processing (NLP) tasks (Devlin et al., 2019; Brown et al., 2020; Rae et al., 2021; Smith et al., 2022; Chowdhery et al., 2023). Efforts at improving the capabilities of these models have revolved around scaling the number of parameters and data (Kaplan et al., 2020; Hoffmann et al., 2022). However, the substantial computational load presents a practical challenge during inference, particularly in resource-constrained applications. To address this issue, Early-Exiting mechanisms (Teerapittayanon et al., 2016; Schwartz et al., 2020; Zhu, 2021; Simoulin & Crabbé, 2021; Bae et al., 2023) have been proposed, thus reducing the inference time without significantly compromising performance. This approach is crucial because while scaling model architectures is beneficial during training, the same amount of compute may not be necessary at inference time for every input, especially for simpler tasks (Geva et al., 2021; 2022). By enabling intermediate layer decoding, Early Exiting offers a promising solution to balance computational efficiency and model accuracy, ensuring that LLMs remain practical and effective in diverse application scenarios.
We analyze the early exiting paradigm for LLMs, conducting a preliminary analysis covering challenges associated with this framework. First, we study a phenomenon of non-finetuned LMs, where the confidence at early layers is deemed to be high, but where accuracy is not satisfactory, thus resulting in poor calibration (Mielke et al., 2022; Band et al., 2024). This gives us grounds to implement some heuristics for the minimum exit layer in our experiments. We repeat the same analysis for fine-tuned models, observing that the phenomena is not as prominent.
We first present a method (Vocabulary Pruning) for increasing model efficiency while remaining confident in the quality of the resulting predictions. Specifically, drawing from Schuster et al. (2022), we modify their Softmax approach, by pruning the vocabulary size across layers. This allows us to speed-up the inference time of our predictions, with a negligible loss in performance. However, in order to offset the decrease in performance, we thus propose within-model Contrastive Decoding (Li et al., 2023) as an alternative means for confidence.
Our methods are validated empirically on different NLP tasks, including text summarization and question answering. Our experiments demonstrate that, combining the two aforementioned approaches, we attain a Pareto improvement with respect to FLOPS efficiency and performance.
Related Works
While the semantic nature of Natural Language is rich, some parts of a sentence often lack variance. In such cases, the number of layers the model has to potentially go through to return the right token is relatively low. Following this intuition, there have been a large number of studies introducing different Early-Exiting frameworks (Teerapittayanon et al., 2016; Schwartz et al., 2020; Simoulin & Crabbé, 2021; Zhu, 2021; Bae et al., 2023; Geva et al., 2021; 2022).
Schuster et al., 2022 investigates Softmax-based confidence measures. Here, the challenge of early-exiting is addressed by introducing a framework that dynamically allocates computational resources per input and generation time-step. The exiting criterium is based on the difference in probits between the two most probable predicted tokens. This ensures a gain in computational efficiency, without excessive performance degradation.
Bae et al. (2023) introduces the (FREE) Fast and Robust Early Exiting framework. FREE uses a shallow-deep module to compute the computational path, hence determining the portion of layers used. Alternatively, Wang et al. (2024) propose a class-based early-exiting strategy. This method leverages the use of intermediate layer features to exclude part of the tokens, allowing later layers to focus on a reduced subset of potential tokens.
Contrastive Decoding (Li et al., 2023) is a technique proposed to reduce unwanted behaviors in LLMs such as hallucinations, repetition, and incoherence. The method employs two models, a smaller one called amateur, and a larger one called expert. They both perform auto-regressive text generation on the same data, and the final predicted token is selected based on the output difference between the predictions of the expert and amateur. However, employing two LLMs is highly inefficient, both in terms of memory and compute. Alternative methods have been proposed, which employ the contrastive decoding scheme, without the necessity of using two models. An example of such work is the idea of Auto-Contrastive Decoding (Gera et al., 2023). The authors show how contrasting outputs of different layers within the same model can benefit text generation outputs. The study shows that predictions of shallow layers can help those of deeper ones to attain better results. Other studies have adapted this technique to different tasks such as reducing hallucination in LLMs (Chuang et al., 2024). Our proposed contrastive decoding techniques are based on both Gera et al. (2023) and Chuang et al. (2024) and adapted to the aforementioned early-exiting framework of Schuster et al. (2022).
Preliminaries and Experimental Setting
Transformer Architecture
The Transformer network, introduced by Vaswani et al. (2017), is structured into $L$ layers, each comprising two distinct sublayers: the Multi-Head Attention (MHA) layer and the Feed-Forward Network (FFN) layer. Within this framework, updates to the residual stream for a subsequent prediction are carried out via the following recursive formula:
\[ h^\ell_t = \text{Transformer}^\ell(h^{\ell-1}_t) \]
where $\ell$ represents each layer from 1 to $L$, and $h_t^0$ denotes the output of the embedding layer $\mathbf{W_E}$. The embedding layer $\mathbf{W_E} \in \mathbb{R}^{d_{\text{vocab}} \times d_{\text{model}}}$, transforms the tokens $y_{1:t}$ having size $d_{\text{vocab}}$, into dense vector representations sized $d_{\text{model}}$.
After processing through the $L$-th layer, the final prediction for the next token, $\hat{x}_{t+1}$, is produced by
\[ p(\hat{x}_{t+1} \mid x_{< t+1}) = \text{softmax}(\textbf{W}_L h^L_{t}) \]
where
\[ \textbf{W}_L \in \mathbb{R}^{d_{\text{model}} \times d_{\text{vocab}}} \]
is the linear classifier of block L responsible for mapping back the output of the FNN at that block from $d_{\text{model}}$ to $d_{\text{vocab}}$.
Our approach incorporates an early-exiting strategy, wherein the generation of the next token can occur at any layer $\ell$ if the computed confidence score $c_\ell$ exceeds a specified threshold $\tau$. When an early exit is triggered at layer $\ell$, it necessitates updating the key and value pairs in subsequent layers to ensure proper attention mechanisms for future tokens. To efficiently manage this, a state copying technique is employed, where the hidden states from the early-exited layer i.e. $h_{t+1}^{\ell}$ are duplicated across subsequent layers ($h_{t+1}^i = h_{t+1}^{\ell}$ for every $i$ such that $i = \ell + 1, … , L$). This process maintains computational efficiency and model performance, even in compact - for today’s standards - model configurations like T5.
Experimental Setting
In this section, we introduce the experimental setting used in both “Methodology” and “Experiments”. We evaluate the encoder-decoder T5 model (Raffel et al., 2020) on two different datasets and two different downstream tasks:
- Stanford Question Answering Dataset (SQuAD) (Rajpurkar et al., 2016): over 100k annotated data, 10k of which used for evaluation.
- SamSum (Gliwa et al., 2019): a human-annotated dataset for abstractive Summarization with more than 800 samples in the Validation set.
Each dataset has its own evaluation metric. Question Answering on SQuAD and Summarization on SamSum will be evaluated via F1 and Rouge-L scores respectively.
Additionally, we compare the performance and effects of our proposed methods on:
- Pre-trained-only version of T5, from t5-large,
- Fine-tuned version of T5, t5-squad, t5-samsum. Both are fine-tuned on the corresponding training dataset.
Our code is heavily based and builds on top of the publicly available codebase fast-robust-early-exit (Bae et al., 2023).
Methodology
Early Exiting via the Softmax Approach
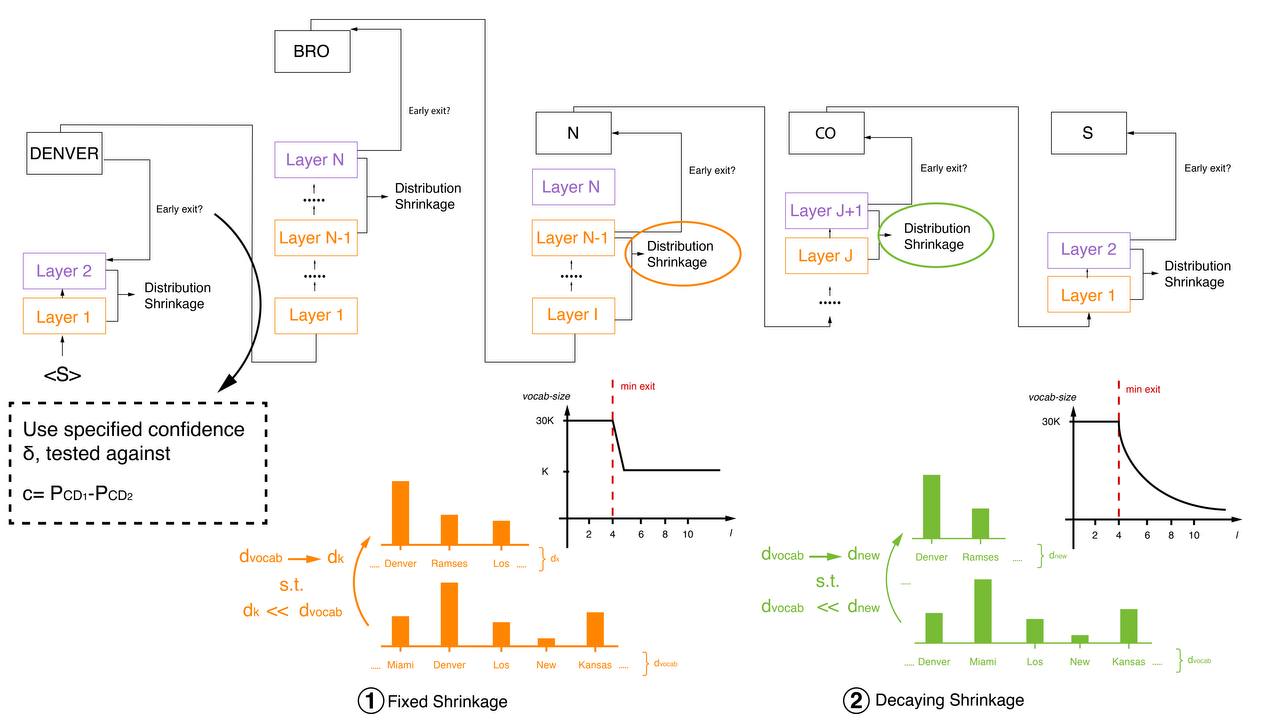
Our first approach (Figure 1) aims to improve a limitation of the Softmax response method introduced by Schuster et al. (2022). We denote the final output of layer $\ell$ as
$\textbf{v}^\ell = \text{Softmax}(\textbf{W}_\ell h^{\ell}_{t})$
The so-called confidence measure is computed as the difference between the top two values of the probits vector $\textbf{v}$, at each layer $\ell$. We denote this measure as $c_{t+1}^{\ell}$. Let us define an early-exit threshold $\tau_{t+1}^{\ell}$ at each layer. If our confidence measure exceeds the early exit-threshold,
\[c_{t+1}^{\ell} \geq \tau_{t+1}^{\ell}\]the model exits early, providing us with the prediction for the next token computed at layer $\ell$. Otherwise, it continues by going into the next Transformer block. However, the matrix multiplication inside Softmax, i.e., $\mathbf{W_\ell} h_{t}^{\ell}$ is computationally expensive, especially when iterated over multiple layers. The exact number of Floating Point Operations (FLOPs) for the above corresponds to $d_{\text{model}} \times d_{\text{vocab}} \times L$. Hence, by pruning the vocabulary size at the first layer from $d_{\text{vocab}}$ to $k$, the number of computations required will reduce to $d_{\text{model}} \times k \times L$.
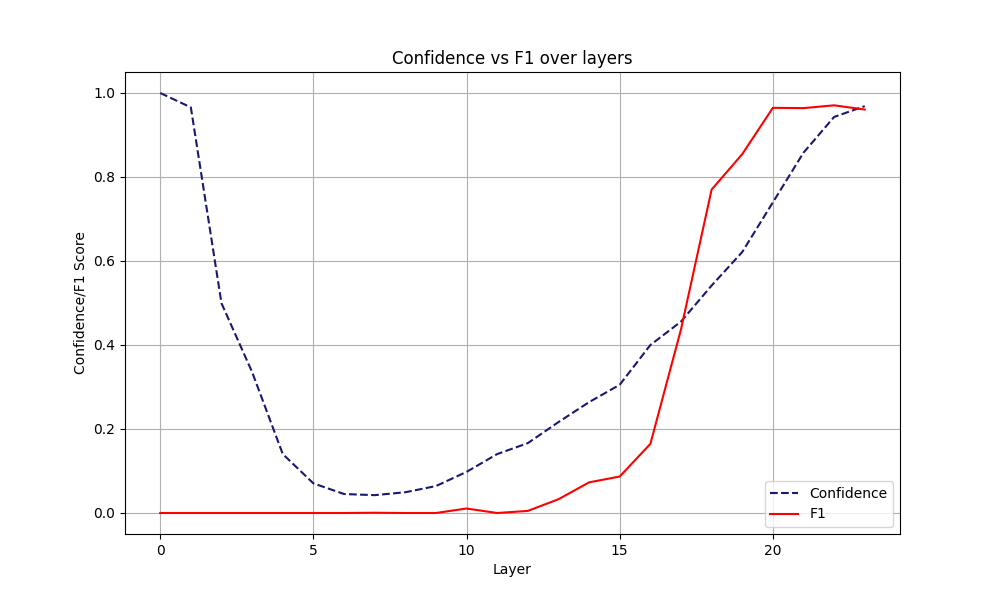
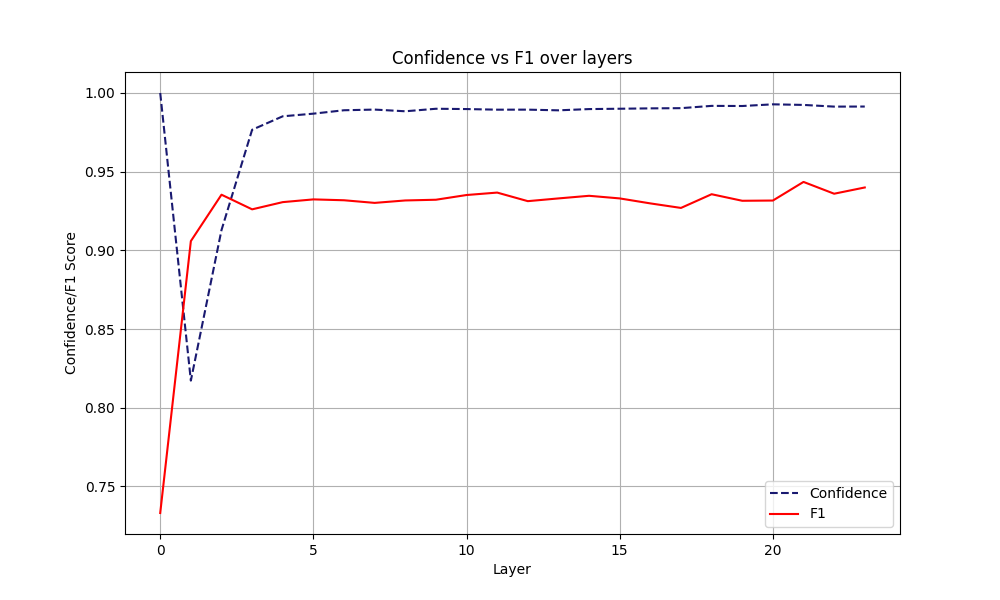
Recall that $\mathbf{W_\ell} \in \mathbb{R}^{d_{\text{vocab}} \times d_{\text{model}}}$, where $d_{\text{vocab}} \approx 32000$ is our vocabulary size, and $d_{\text{model}}$ is equal to the size of the last hidden representation of our FFN. Both parameters are on a scaling upward trend in SOTA architectures. We argue that most of these computations are redundant, and potentially not necessary for some tasks. In Figure 2, we show the boxplots for the rank of the final predicted token at each layer, across not fine-tuned and fine-tuned models, for two different datasets. The main takeaway from these images is that the final predicted token is often already highly ranked from the first few layers of our model. This behavior is more explicit in Figures 2b and 2d, where we use fine-tuned models on our downstream tasks. On the other hand, confidence alone can be a deceiving measure. LLMs can be overconfident in the first layers, causing the model to exit prematurely. Our desiderata is for the model to be confident at the same time when its prediction has a high accuracy, that is, to be calibrated. However, we interestingly note that such behavior is rarely observed at early layers. In Figures 3 and 4, we see the accuracy and the confidence across each layer. The model in the first layers presents an anomalously high confidence, while its performance is still poor. Early exiting only based on the Softmax response would result in bad performance. We decide to set a minimum exit layer parameter $j$, which forces the model to consider exiting only after this layer. Note that this parameter is highly dependent on the model and dataset one experiments on. For fine-tuned models for example, one expects this parameter to be smaller.
Motivated by these findings, we introduce three additional modifications to the Softmax response approach.
Softmax response via fixed vocabulary pruning After the minimum early exit layer $j$, we prune $\textbf{W}_{j+1}$, retaining its top-k tokens in the new unembedding matrix. We define the size of the new pruned matrix as
$$ \large \tilde{\textbf{W}}_{j+i} \in \mathbb{R}^{d_{\text{model}} \times k}, \quad \textrm{for} \quad i = 1, \ldots, L-j \quad \textrm{and} \quad k \ll d_{\text{vocab}} $$
The size is kept fixed to $k$ for all subsequent layers. Theoretically, calculating the ratio between the original number of computations required in the original approach and ours, we get
$$ \large \frac{d_{\text{model}} \times d_{\text{vocab}} \times L}{d_{\text{model}} \times k \times (L - j) + d_{\text{model}}\times d_{\text{vocab}} \times j} $$
which corresponds to an approximate efficiency gain in the order of
$$ \large \mathcal{O}\left(\frac{d_{\text{vocab}}}{k} \times (L-j)\right) $$
Softmax response via decaying vocabulary pruning
As one can note from Figure 2, the rank of the predicted token smoothly decreases across layers. Similarly, we start by pruning the $\textbf{W}_{j+1}$ matrix, given a minimum early exit layer $j$. We retain its top $k$-tokens, obtaining
$$ \large \tilde{\textbf{W}}_{j+i} \in \mathbb{R}^{k \times d_{\text{model}}} $$
Now, instead of keeping the reduced matrix size fixed, we further prune it at every successive layer. Given $\tilde{\textbf{W}}_{j+i}$ of size $k_1$, we prune it at layer $j+i+1$ to a reduced matrix of size $k_2$, where
$$ \large k_2 = \max\left( k^*, \frac{k_1}{1 + \frac{k_1 - k^*}{k^*} \cdot \frac{j + i}{\text{num\_layers}}} \right) $$
$k^*$ here indicates a lower bound on the size $\tilde{\textbf{W}}_{j+i+1}$ can reach. The function we define has been chosen based on Figure 2a, hence to be robust against the worst-case scenario. It approximates the decay in the ranking of the top-k token in that case. The efficiency gain is even more prominent than in the case of fixed pruning.
Softmax response via adaptive vocabulary pruning
It can be seen in Figures 3 and 4 that, after a few blocks, the confidence and the F1 score of each layer are highly correlated. Together with Figure 2, this poses a basis for an approach where the amount of retained top-k tokens at each layer is adapted to the confidence at the previous one. We propose the following:
$$ \large k^\ell = \text{vocab\_size} \times (1 - \text{confidence}^{\ell - 1} \times \text{scaling_factor}) $$
Where $k^{\ell}$ is the amount of retained tokens at layer $\ell$, $vocab_size$ is the size of the full vocabulary, $\text{confidence}^{\ell - 1}$ is the confidence at layer $\ell - 1$, scaling_factor is a coefficient that is introduced to avoid retaining 0 tokens in case of confidence = 1. For simplicity, this has been set to 0.9 during our experiments.
To summarize, our final predicted token is often highly ranked across all layers. Due to this, pruning the vocabulary matrix allows us to reduce the amount of computations at each block, discarding only irrelevant tokens. While we may potentially trade-off some performance, this further speeds up the runtime of our model, allowing us to obtain considerable efficiency gains.
Measuring Confidence Via Contrastive Decoding
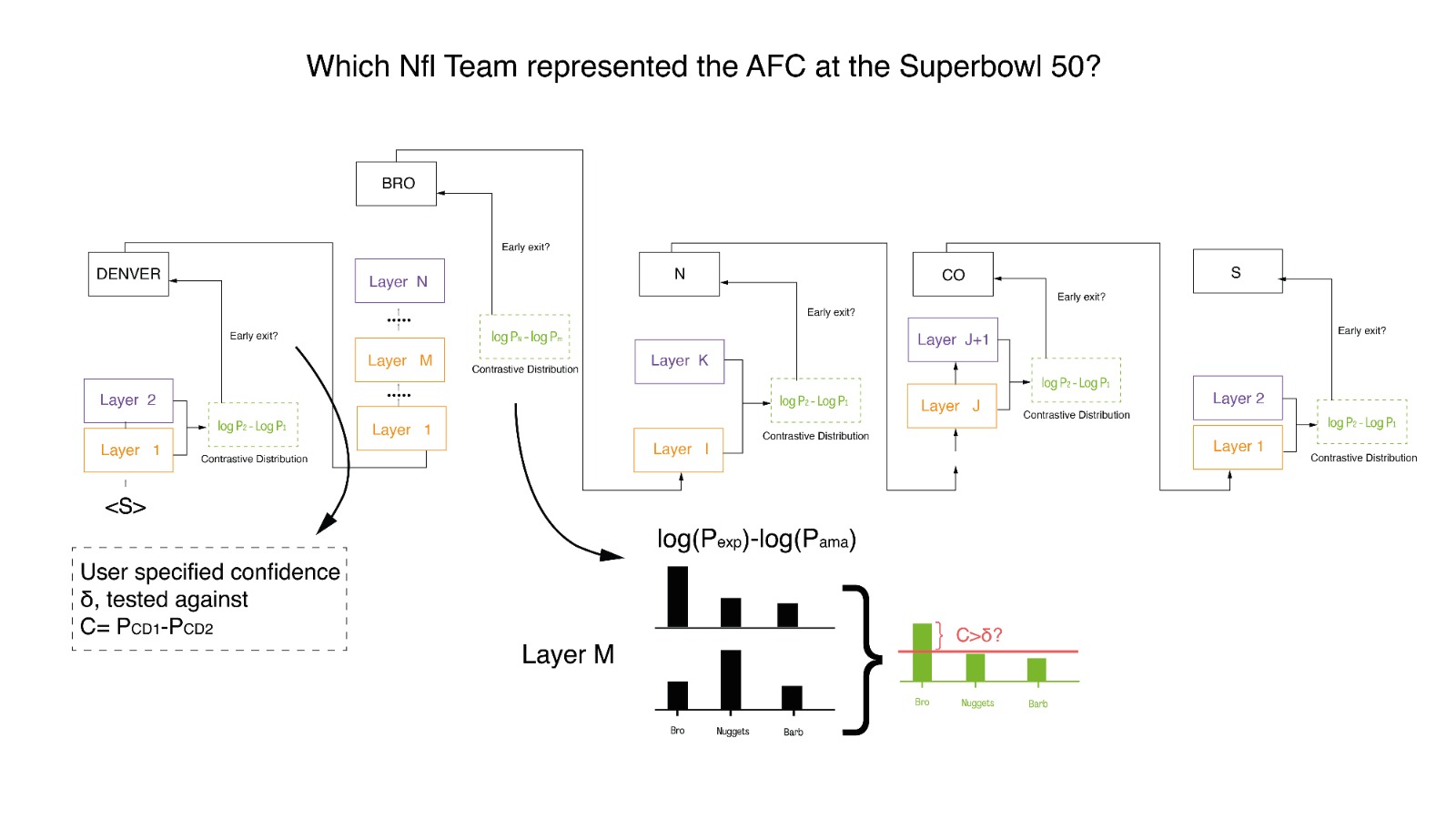
The second approach (Figure 5) is inspired by Li et al. (2023). We propose to apply their framework to address one of the limitations of Schuster et al., 2022. Namely, as introduced in previous sections, the Softmax response approach relies on a static notion of confidence, which depends only on the probability distribution computed at the current layer. Such approach may ignore the evolution of the probits’ magnitudes across the model.
By contrasting the outputs of smaller LMs with larger ones, Contrastive Decoding (CD) accounts for the difference in representations computed by amateur and mature layers. The core goal of this method is to refine the output distribution by filtering through the lens of larger models, retaining only their superior linguistic predictions. The original implementation involves the use of two models in parallel, returning the log-ratio between the probits $p_{\text{EXP}}$ of a large LM - called the expert - and the probits $p_{\text{AMA}}$ of a small LM - called the amateur.
Naturally, this captures the dynamical change of the token’s distribution when computed at different heights of the Attention’s stack.
Following Li et al. (2023), we first implement the CD adaptive plausibility constraint, $\nu_{\text{head}}(x_{< t})$, defined as:
$$ \large \nu_{\text{head}}(x_{< t}) = \{x_t \in V : p_{\text{EXP}}(x_t|x_{< t}) \geq \alpha \cdot \underset{x'_t \in V}theme (p_{\text{EXP}}(x'_t|x_{< t}))\} $$
where $V$ is our vocabulary.
It’s important to recognize that smaller LMs, despite their limitations, do reliably capture basic elements of English grammar, such as subject-verb agreement. Applying the CD objective indiscriminately could penalize these correct linguistic behaviors, leading to false negatives. It might also erroneously reward implausible token choices, resulting in false positives. To address these potential pitfalls, we incorporate the plausibility constraint $\nu_{\text{head}}$ into our framework. Given a preceding context $x_{< t}$, this constraint selects a subset of plausible next tokens, out of the vocabulary $V$, whose probabilities are above a threshold. The threshold is a fraction $\alpha$ of the max probability token in the vocabulary. We set the hyperparameter $\alpha \in[0, 1]$ to 0.1, as done by Li et al. (2023). Borrowing from Gera et al. (2023), the contrastive objective, called Log Contrastive Difference (LCD), is defined as:
\[\large p_{\text{LCD}}(x_t | x_{< t}) = \text{Softmax}\left(\log \frac{p_{\text{EXP}}(x_t | x_{< t})}{p_{\text{AMA}}(x_t | x_{< t})}\right) \sum_{x_t \in V_{head}(x_{< t})} p_{EXP}(x_t | x_{< t})\]The LCD objective is designed to promote text patterns that are preferred by the expert LMs and discourage those that are typically produced by the amateur LMs. It works in tandem with the plausibility constraint, to ensure that the penalization of amateur behaviors does not disregard grammatically correct and sensible language constructs. The final distribution will be:
\[\large p_{\text{DCD}}(x_t | x_{< t}) = \begin{cases} p_{\text{LCD}}(x_t | x_{< t}) & \text{if} \ x_t \in V_{\text{head}}(x_{< t}) \\ p_{\text{EXP}}(x_t | x_{< t}) & \text{otherwise} \end{cases}\]We utilize this defined distribution to compute the new confidence $c^{\ell}_t$. By doing so, we overcome the static nature of the confidence measure usually considered in the Early-Exiting literature.
On the other hand, we remind that our approach is based on the use of one single model.
Building upon Gera et al., 2023, we include their variant of auto-contrastive decoding into our early-exiting framework. Here, $p_{\text{EXP}}$ and $p_{\text{AMA}}$ are respectively proxied by the current layer $\ell$ and by the layer $\lfloor{\frac{\ell}{2}}\rfloor$. This intuition is aligned with findings by Elbayad et al. (2019) and Geva et al. (2021); Geva et al. (2022). We will refer to this auto-contrastive decoding strategy as “Weighted Contrastive Decoding”. One question that arises from this idea is the previous layer selection. Clearly, this choice of the amateur layer is very arbitrary.
We tackle this problem drawing from Chuang et al., 2024. The authors suggest selection via distance-in-distribution through Jensen-Shannon Divergence. This way, they claim, it is possible to find the most fit amateur layer. They do so by contrasting the final distribution against a set of candidate possible premature layers. The layer selected as the one with highest JSD w.r.t. the expert one. They also divide the layers into 2 to 4 buckets of $J$ based on the total number of layers, relying on a validation set to choose the best bucket for each task. Our claim is that the bucketing strategy is suboptimal for several reasons. First, it requires task-specific selection, which is undesirable since these models are utilized by end users for open-ended generation. Second, bucketing does not address the implicit bias JSD will have towards the lower layers of the distribution. Earlier representations are necessarily more diverse, since the set of plausible tokens for autoregressive generation gets narrower as one goes deeper into the stack. For this reason, we discount the JSD value between two distributions $i, j$ by the layer distance $\ell_j - \ell_i$. The discounting allows us to capture the layers at which there is a more significant distribution change w.r.t. the one we find ourselves at, thus obtaining a meaningful signal from the chosen contrastive distribution.
Consider the current expert layer $\ell$, and set of plausible amateur layer $J = { 2, …, L-1 }$. The selected layer $m$ is obtained as
$$ \large m = \underset{j\in J}{\text{argmax}} \frac{1}{\ell - j} \text{JSD} (p_{\ell}(x_t | x_{< t}),p_{j}(x_t | x_{< t})) $$
To illustrate the above method, in (Figure 6) we show the JSD contrast on a given sample.
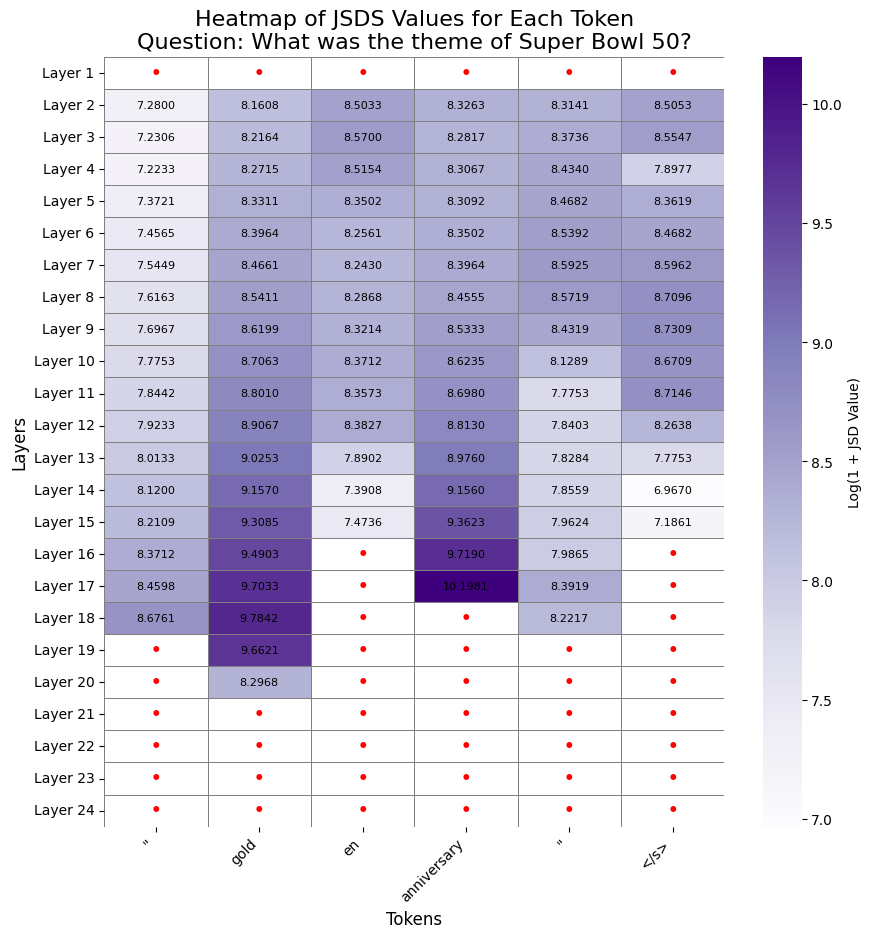
We will call this technique “Jensen-Shannon Divergence (JSD) Contrastive Decoding”.
Finally, to get the best of both worlds, we experiment with a mixed approach between Contrastive Decoding and Softmax pruning. The rationale here is that we can combine the CD confidence measure together with the relevant top-k tokens in the logits we find with the pruning done for the Softmax vocabulary pruning approach.
Experiments
Softmax Speed-Up
In this section, we report the results of the different Softmax vocabulary reductions applied to the $\textbf{W}_{j}$ matrix. The aim is to achieve similar performance with regards to the evaluation metrics, while significantly reducing the amount of FLOPs required. We implement the previously proposed approaches and perform our experiments by building on the available codebase implementation. The minimum exit layer is based on the lowest confidence level found in Figure 3 and Figure 4. We run experiments, either with the Fixed or Decaying approaches, as presented in Section “Early Exiting via the Softmax Approach”. We evaluate the models based on their respective performance metrics and the number of floating point operations (FLOPs). The evaluation is conducted for both the Question-Answering (see Figure 7) and Summarization task (see Figure 8).
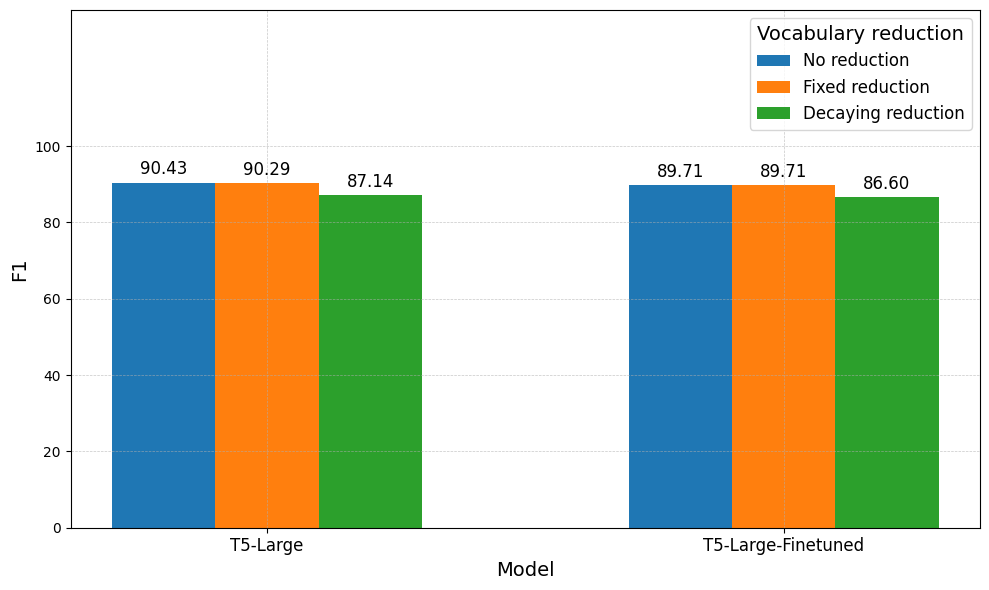
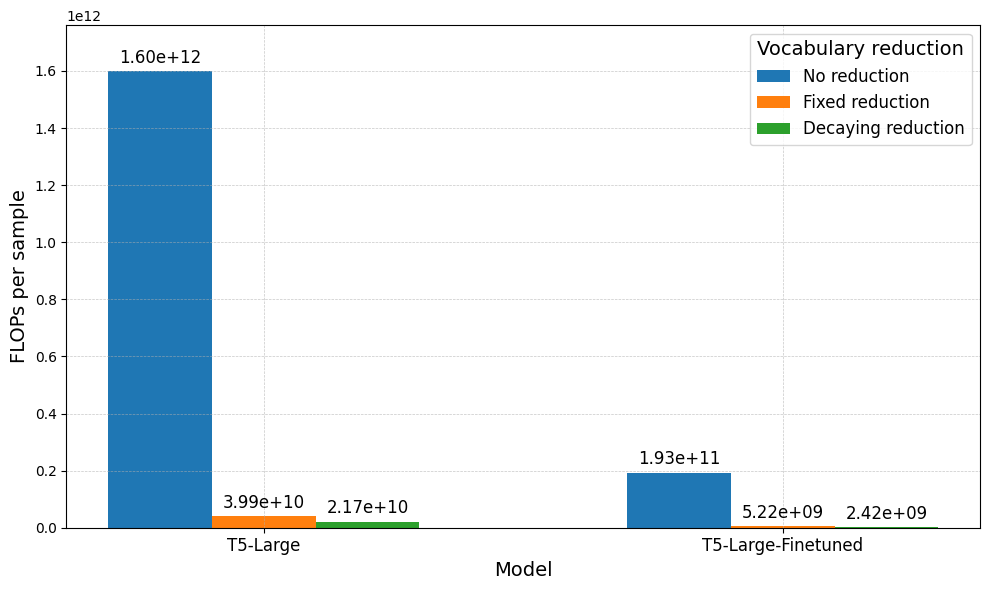
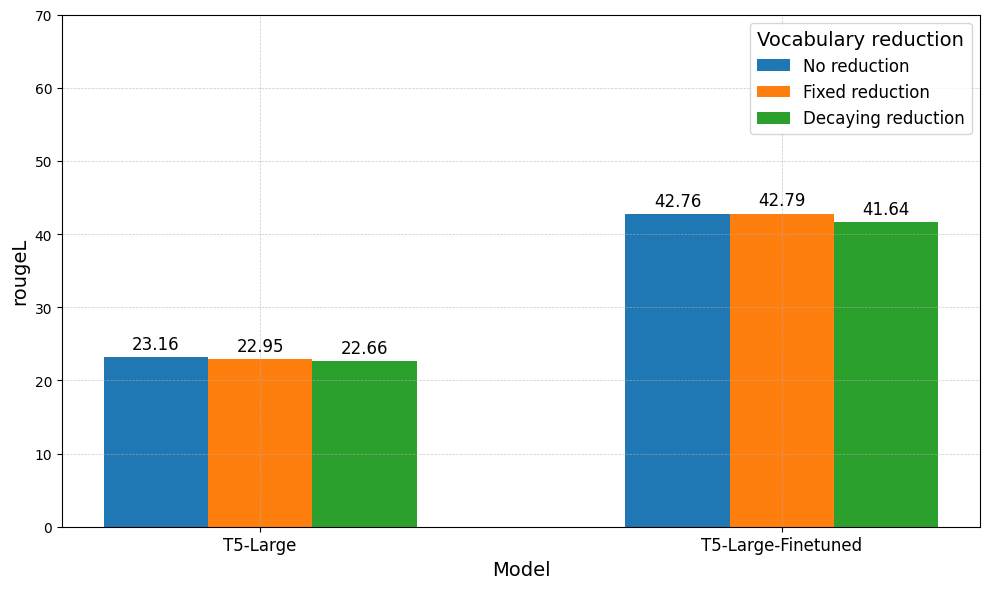
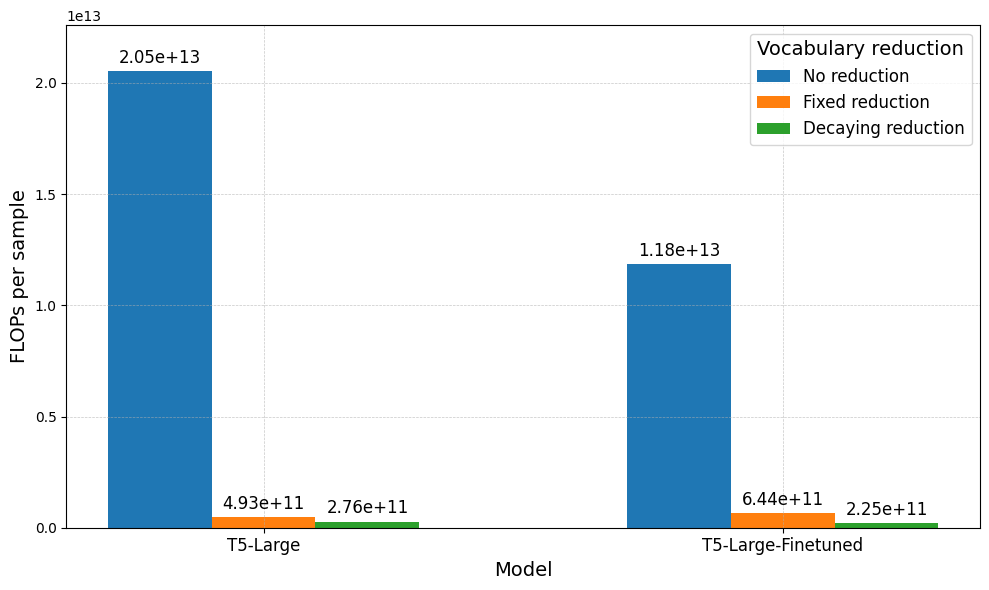
Both plots display the following trend: similar performance is achieved across the evaluation metrics, but the amount of FLOPs decreases by a factor of 100x. Additionally, comparing Fixed and Decaying reduction, half of the FLOPs are utilized by the latter, which however incurs a 2% loss in performance. This illustrates the trade-off: choosing a smaller $k$ reduces the number of FLOPs but at the cost of a degrading performance. Additionally, due to fine-tuned models exiting at earlier stages, fewer FLOPs are computed overall. However, the same trade-off remains. We set the threshold $\tau^{\ell}_{t}$ required for exiting at 0.9 across all layers. It is important to note that if this value were lowered, our model would exit earlier, hence producing faster but more inaccurate and less confident predictions.
Contrastive Decoding
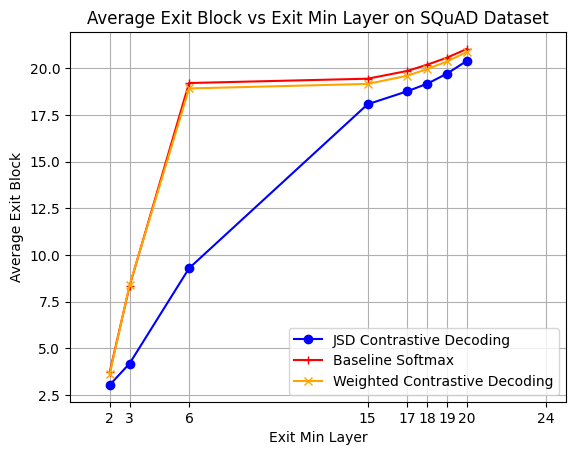
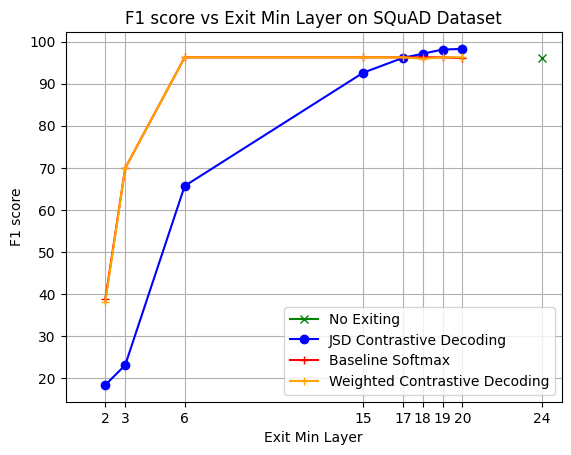
In this section, we analyze the behavior of the two implemented versions of Contrastive Decoding confidence measures, Weighted and Jensen-Shannon Divergence (JSD). The goal of this section is to illustrate the impact of CD on the performance and average early exit of the model.
Results from Figure 9 show Weighted contrastive decoding achieving comparable average exit layer with Softmax baseline by (Schuster et al., 2022), while still retaining almost all the performance. More interesting is the behaviour of JSD, which consistently beats the Softmax baseline. The method is exiting earlier with an average gain of 2.5 blocks, while also achieving higher performance with a 2\% increase over the no-exiting baseline (green dot).
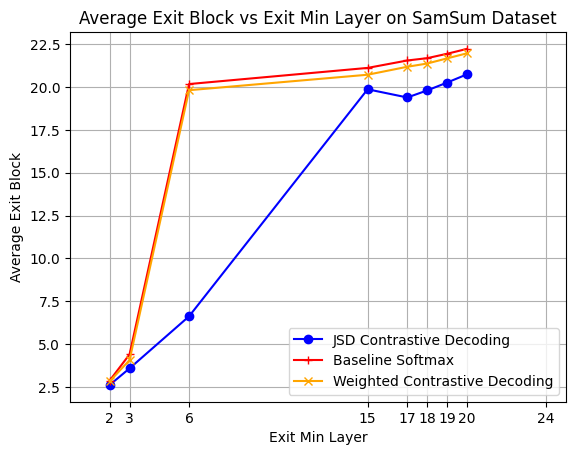
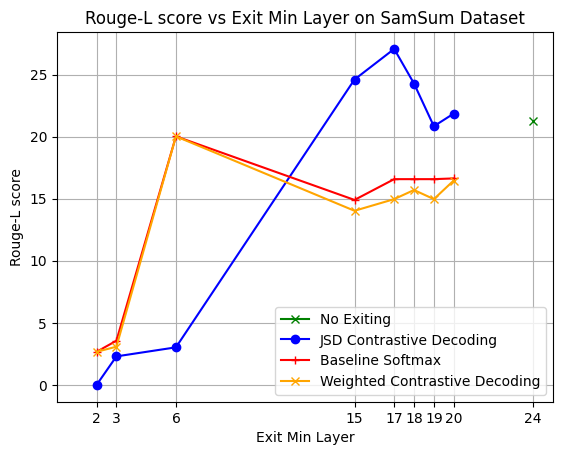
Evaluation on SamSum dataset, Figure 10, shows notable results. While Weighted Contrastive Decoding is on par with the Softmax baseline, the JSD confidence measure is exiting earlier on average, with a 2.9 block gain against Softmax (red line). Additionally, JSD is attaining an approximate 10\% increase in Rouge-L performance if setting the minimum exit-layer to 17.
Speedup and Contrastive Decoding
JSD has shown significant performance gains with respect to Softmax and Weighted Contrastive Decoding. In this chapter, we merge JSD with Softmax vocabulary pruning. We then compare the best Softmax vocabulary pruning with Contrastive Decoding against the previously analyzed individual baselines. We show that combining JSD technique with a compute efficient pruning mechanism positively impacts results. We will report the average exit block, the performance score, and the computed FLOPs.
Best JSD Pruning Combination
We perform a series of experiments aimed at understanding the best possible vocabulary pruning method for the best CD confidence measure.
Following the argument in “Contrastive Decoding”, we observe that the model is most performant when the minimum exit layer is selected to be among the latest ones. Keeping this in mind, Table 1 shows the average exit layer and score of the model. Both are averaged across these sensible minimum exit layers. We note that combining Adaptive Pruning with JSD beats the performance of JSD combined either with Fixed or Decaying pruning. It also obtains an average gain of 1.2 blocks against Fixed pruning on SamSum. However, JSD+Fixed achieves the highest Rouge-L score in SamSum. Given the considerations above, we choose Adaptive to be the most fitting pruning method to combine with the JSD confidence measure. We defer to Appendix A a series of detailed plots indicating all minimum exit layers in this setting.

Comparison Across different pruning methodologies applied to Jensen-Shannon Divergence (JSD) confidence measure. The values in the table are the mean of exit/performance over 15, 17, 18, 19, 20 as early minimum exit layer ± their standard deviation. Due to time and compute constraints, the results displayed are computed on 100 samples.
Comparison with Baseline Models
Given the results of “Speedup and Contrastive Decoding”, together with our analysis of the best minimum exit layer to use in CD, we now compare the most performing pruning method of “Best JSD Pruning Combination” with the baselines from “Contrastive Decoding” and “Softmax Speed-Up”. We set the minimum exit layer at 19 for all the experiments below.
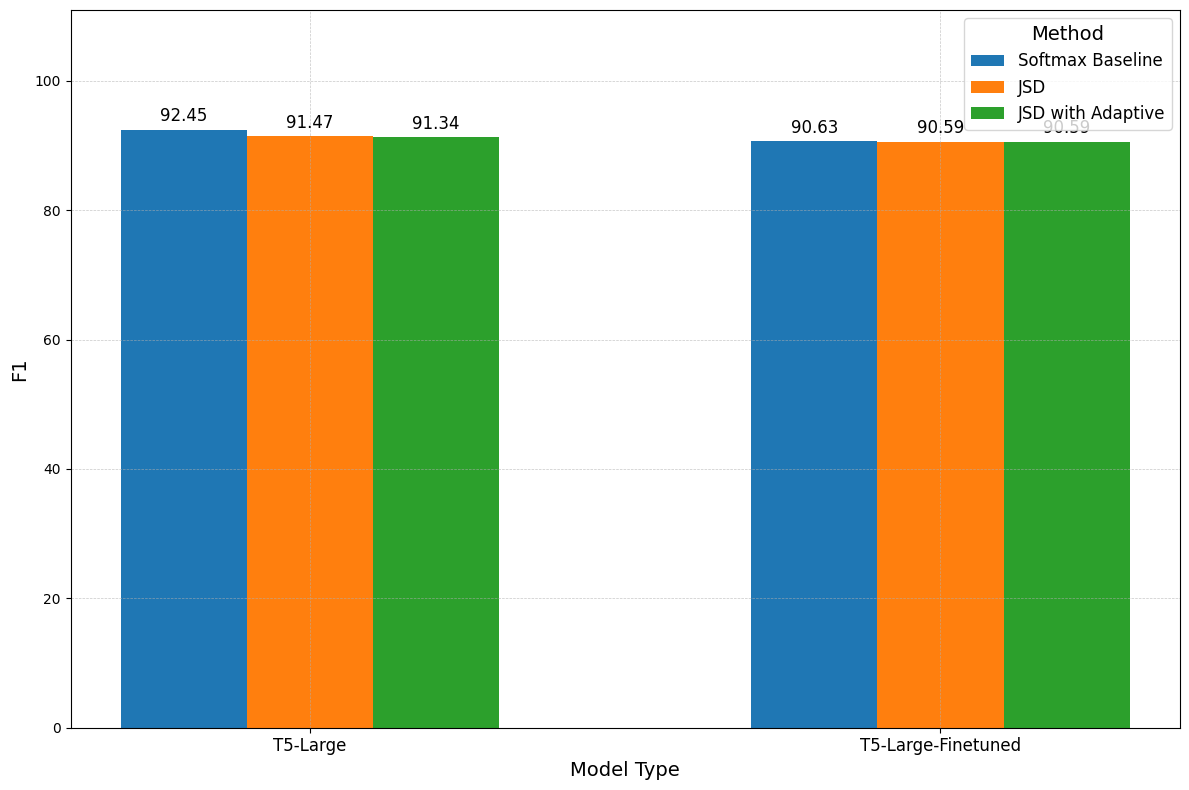
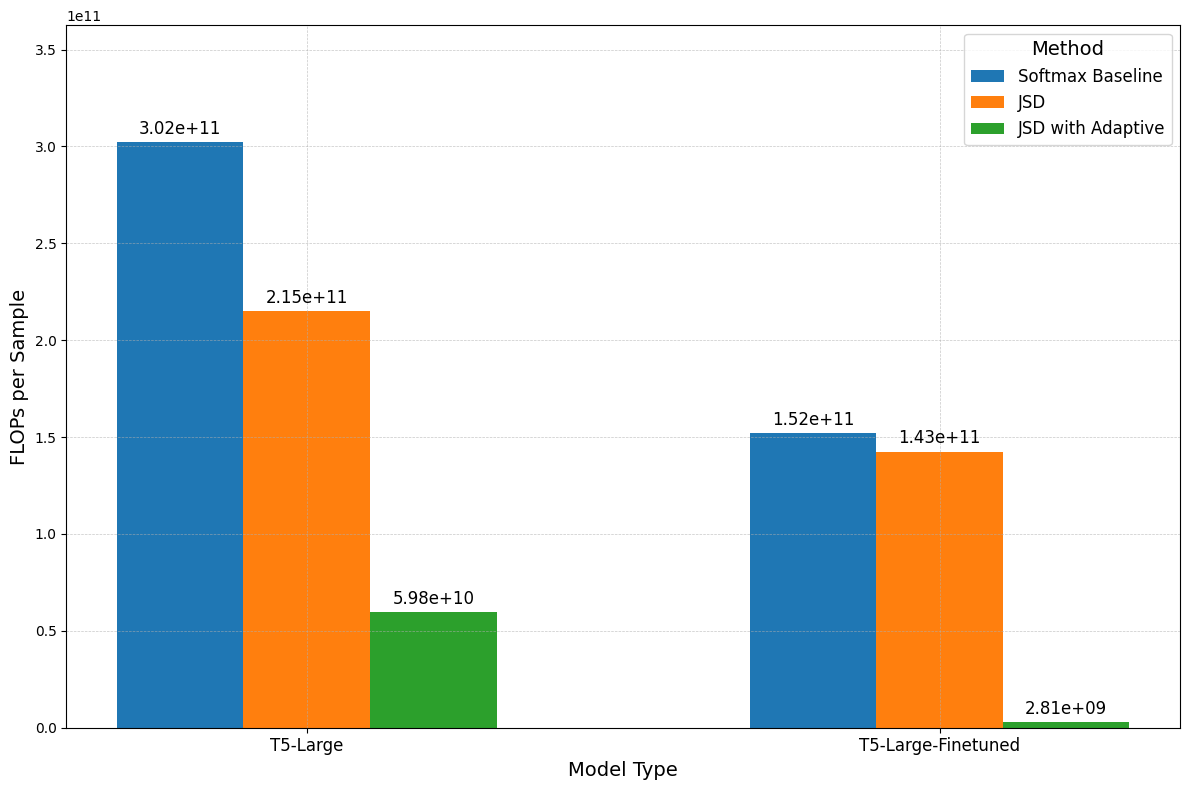
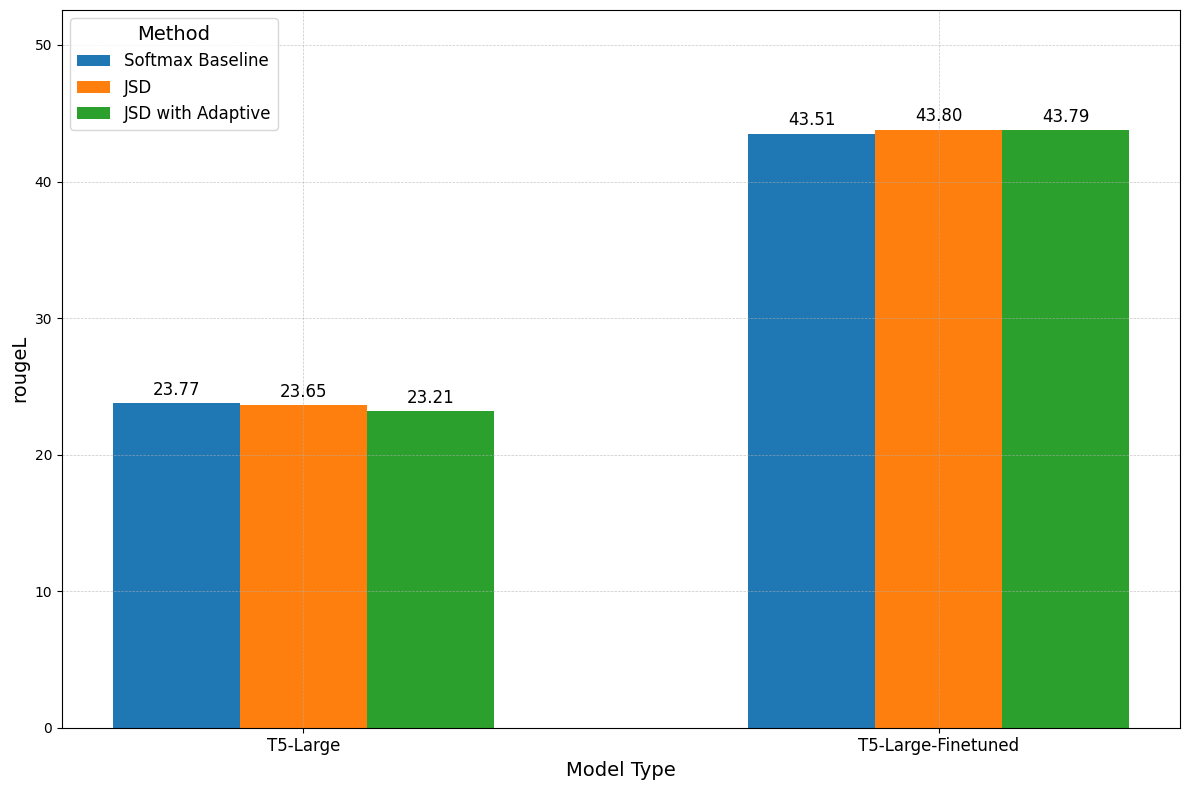
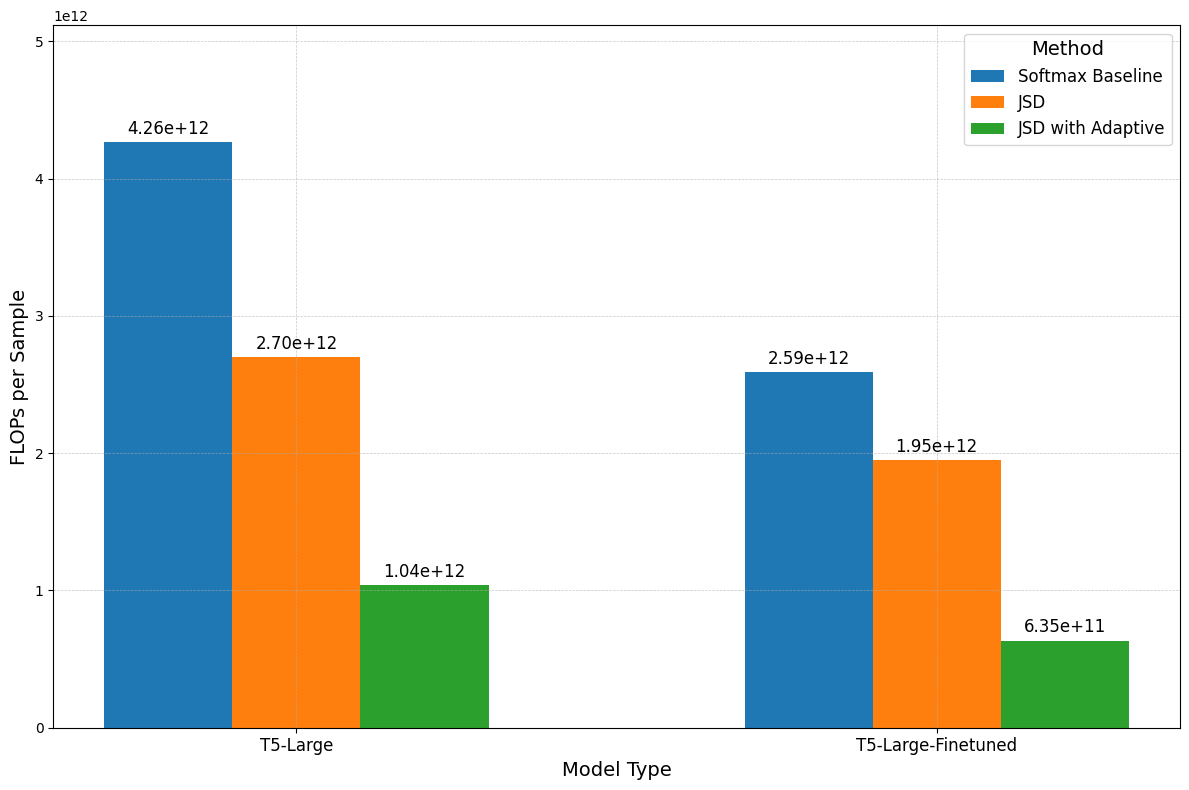
In “Softmax Speed-Up” we show the considerable impact the pruning approach has on FLOPs. Similarly, Figures 10 and 11 show that removing a large number of tokens has a notable effect on compute, reducing it by almost 100 times on SQuAD and 10 on SamSum between JSD baseline and JSD with adaptive pruning. This gap is also more noteworthy when looking at the amount of performance retained. On both fine-tuned and non-finetuned models the decrease in performance between the downstream tasks is never more than 1.5%, with JSD. Lastly, we highlight the difference in results between Figure 7, 8, and Figure 10, 11, due to a higher minimum exit layer selected for the former experiments. However, in both cases, our results are consistent both in trend of terms and performance and FLOPs reduction.
In conclusion, combining a vocabulary reduction approach, together with a confidence measure method, allows us to compute considerably fewer FLOPs, while retaining the performance with respect to Softmax and JSD baselines.
Conclusion and Future Work
In this study, we have explored the application of early exiting strategies within Large Language Models (LLMs) to address the challenge of computational efficiency during inference. Our research integrates traditional early exiting mechanisms with concrete gains in efficiency obtained from vocabulary pruning. Additionally, we apply the idea of Contrastive Decoding to the early exiting setting, showing how this approach can be used as a confidence measure, by imposing a clever heuristic on the choice of the layer to contrast to. Lastly, we combine the aforementioned techniques and demonstrate that we can both retain almost all performance, while still carrying out a considerably lower number of FLOPs during inference. This results in a solution that satisfies both the efficiency and score performances we aimed for.
In future work, a natural follow-up is the use of the Contrastive Decoding output as the resulting output to perform the prediction on. Moreover, sensible investigations about the distributional distance and specific interventions on the computation of the contrastive distribution can be considered.
On an empirical note, we aim to expand our analysis to include a wider array of tasks - machine translation, open-ended generation, and long context tasks - and evaluation on larger datasets to further validate our proposal. Another limitation is that the overall runtime performance does not always match the improvements seen in FLOPs. This discrepancy is largely due to the hyper-optimization of the PyTorch library, which optimizes matrix multiplications, thereby reducing overall runtime, though it is worth noting that our gains in FLOPs should increase as a function of model scale. Additionally, since we are working with pre-trained tokenizers, reducing the $W_j$ matrix leads to incorrect predictions, necessitating a remapping back to the original vocabulary size. This process introduces an overhead that further worsens runtime, as we are forced to apply the same operation twice (reducing first and then expanding again). Several engineering-reliant optimizations are still possible in this direction, which were not explored due to the previously mentioned constraints. With regards to vocabulary reduction, the function that shrinks the $k$ values is based on the worst-case scenario observed in the data (see Figure 3). This function could be adjusted depending on both the problem type and the LM employed. For instance, a finetuned model as depicted in Figure 2b might benefit from more aggressive shrinkage compared to its non-finetuned counterpart. Additionally, we plan on further refining the integration of the vocabulary pruning method with Contrastive Decoding. We hypothesize that, by leveraging the list of top-k tokens within Contrastive Decoding, we can get rid of the plausibility constraint, overall reducing further reliance on hyperparameter settings and tuning. All these reasons inspire us to further work in this promising direction, and we hope the same applies to the reader.
Citation
If you use this work, please cite:
@misc{vincenti2024dynamicvocabularypruningearlyexit,
title={Dynamic Vocabulary Pruning in Early-Exit LLMs},
author={Jort Vincenti and Karim Abdel Sadek and Joan Velja and Matteo Nulli and Metod Jazbec},
year={2024},
eprint={2410.18952},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2410.18952},
}
@misc{abdelsadek2024optimizing,
title={Optimizing Predictions: Vocabulary Reduction and Contrastive Decoding in LLMs},
author={K. A. Abdel Sadek and M. Nulli and J. Velja and J. Vincenti and G. Desimini},
year={2024},
url={https://matteonulli.github.io/blog/2025/earlyexit/},
}
References
Enjoy Reading This Article?
Here are some more articles you might like to read next:
Enabling Vision in Language Models