Model Compression for Machine Translation in Large Language Models
M. Nulli, J. Vincenti, A. Tragoudaras, Z. Tzifa-Kratira, and A. B. Gomez
University of Amsterdam
📄 Paper | 📝 Blogpost | 🧑💻 Code
Motivation
Small traditional machine translation models can produce high-quality translations in a one-to-one language setting [1]. However, when scaling these models to handle multiple languages, they often struggle to perform well due to the limited amount of parallel data and the complex architectures required to fully understand the task. In contrast, Large Language Models (LLMs) [2] can handle complex settings due to their large architectures and overcome smaller datasets by leveraging their large English training data. As a result, ALMA is a fine-tuned LLM designed for machine translation across multiple language directions from and to English and is the first LLM to become competitive with traditional machine translation models [3].
Despite performing remarkably well in translation, ALMA incurs significant computational and memory costs, making even inference prohibitively expensive to scale to consumer hardwar [4]. To address these challenges, several compression techniques have been proposed for LLMs. Among many others, these include quantization [5, 6] and pruning [7, 8, 9] methods. However, none of these techniques have been applied to ALMA and evaluated in terms of translation quality.
In this work, we explore applying compression techniques to ALMA to preserve its translation quality. We experiment with five distinct compression methods: GPTQ [10], Q-LoRA , [11], SmoothQuant [12], Wanda [13], and DSnot [14]. To evaluate the effectiveness of these techniques, we assess their translation quality, memory usage, and inference time, providing a comprehensive analysis of the trade-offs involved in compressing LLMs fine-tuned for translation.
Results
Table 1 presents the results for the five different compression techniques. A noticeable performance gap can be observed between the en→xx and xx→en translation directions. As noted in [3], this disparity is likely due to the large amount of English data used during the training of LLAMA 2 [15], resulting in a bias towards better performance when translating into English.
en ↔ x. Additionally, we cover the average time per token in seconds (↓) and the memory allocation in megabytes (MB) (↓) after each compression technique is applied. Quantization
All quantization methods preserved strong BLEU and COMET performance—only slightly below the baseline—while reducing memory use by about 70%. This stability likely stems from ALMA’s already low BLEU score and highly variable multilingual weights, which allow better generalization after quantization. However, 4-bit quantization increased inference time, likely because GPU operations still rely on FP16 multiplications, which are more efficient on current hardware despite the smaller memory footprint of integer formats.
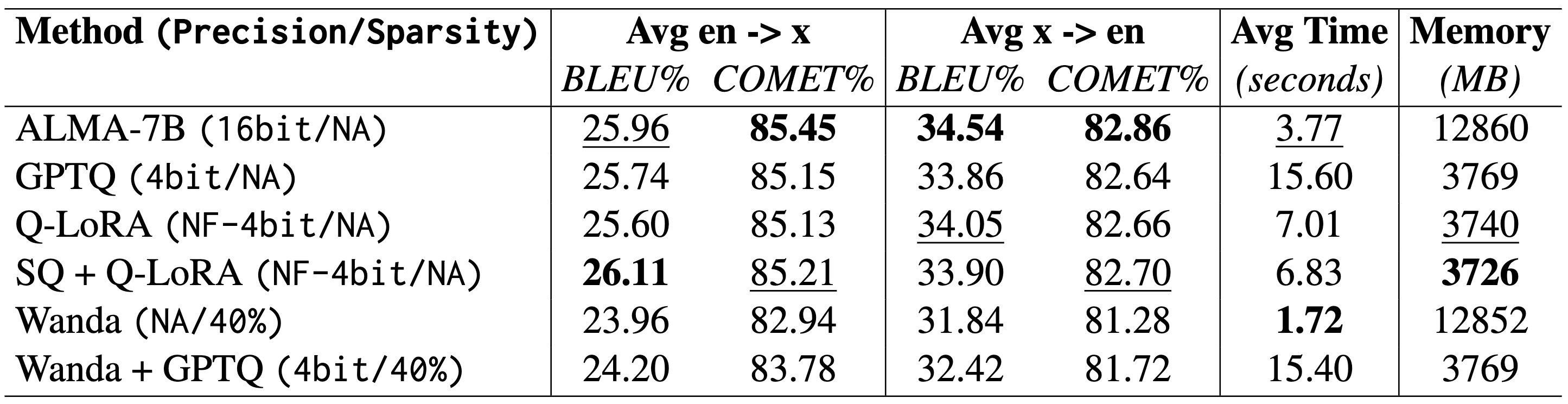
The GPTQ study in Figure 1 found that 4-bit quantization offers the best balance between performance and memory efficiency, while 2-bit causes major degradation due to limited representational capacity. However, GPTQ also led to increased inference time, likely because the fused kernel optimization from the original paper was not implemented (2nd Row Table 1).
The Q-LoRA-like quantization method showed minimal translation performance loss and faster inference than GPTQ (3rd Row Table 1), thanks to its efficient block-wise floating-point quantization and de-quantization to FP16.
Finally, combining SmoothQuant with Q-LoRA by smoothing activations and applying block-wise weight quantization—surprisingly improved performance beyond the baseline ALMA-7B (4th Row Table 1), suggesting that quantization can also act as a noise-suppressing mechanism that enhances translation quality.
en ↔ x across different GPTQ bitquantization levels. The bottom bar chart represents the memory allocation across different precision values. Both results are based on ALMA-7B. Pruning
Wanda pruning achieved lower BLEU scores but offered faster inference and reduced memory use compared to the full ALMA-7B model (5th Row Table 1). However, its memory savings were less substantial than quantization, since pruning zeros out weights rather than compressing them. The resulting sparsity speeds up computation but does not reduce the number of operations.
Wanda + DSnoT improved perplexity (predictive accuracy) but had negligible gains in BLEU and COMET, indicating that it enhances word-level prediction rather than overall translation quality. Thus, DSnoT appears better suited for general LLM tasks and was excluded from the main results.
Wanda + GPTQ, inspired by prior LLaMA experiments, combined pruning (50% sparsity) with 4-bit quantization, yielding slightly better performance and memory usage comparable to pure quantization, though with longer inference times (6th Row Table 1). The method’s suitability ultimately depends on the hardware and performance trade-offs of the translation setup.
Effects of Calibration
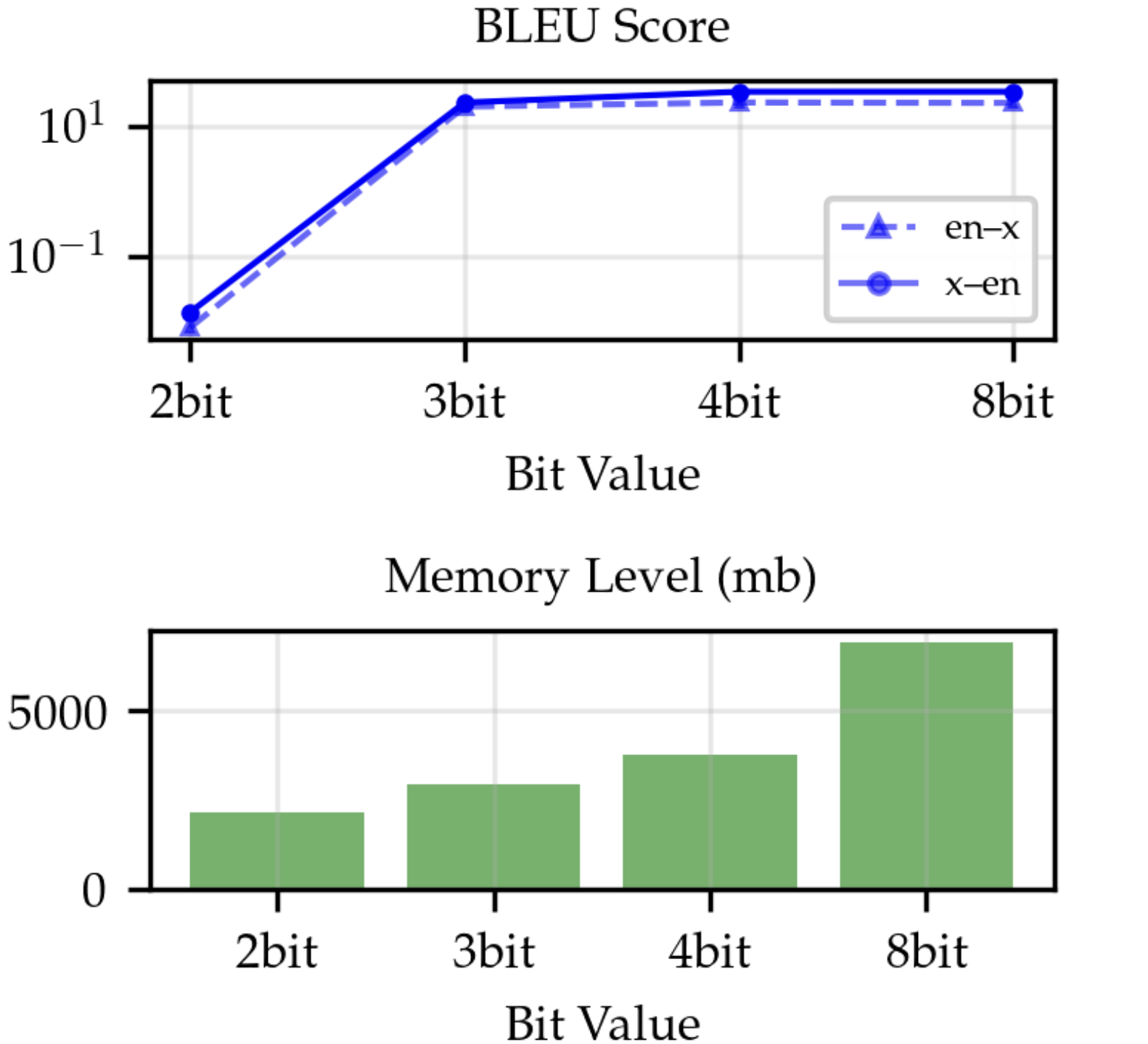
In Figure 2 we report our expeirments on calibration data. These showed minimal performance differences across varying sample sizes, suggesting that translation models depend mainly on pattern recognition and word mappings, which smaller datasets can capture effectively. Since calibration is a one-time post-training step, using the best-performing setup (512 samples per language) is acceptable despite higher latency. However, as model size increases, calibration becomes computationally expensive, highlighting the advantage of methods like Q-LoRA, which bypass the calibration step entirely.
en ↔ x across varying calibration sizes and different compression methods. All results are based on the ALMA-7B model. Citation
If you use this work, please cite:
@misc{nulli2024modelcompression,
author = {Nulli, M. and Vincenti, J. and Tragoudaras, A. and Tzifa-Kratira, Z. and Gomez, A.},
title = {Model Compression for Machine Translation in Large Language Models},
url = {https://matteonulli.github.io/blog/2024/alma/},
year = {2024}
}
Enjoy Reading This Article?
Here are some more articles you might like to read next:
Enabling Vision in Language Models