-
Demystifying Multimodal Learning: The Hidden Inefficiency in Vision Language Modelling
A blogpost series on the nuts and bolts of Multimodal Learning

-
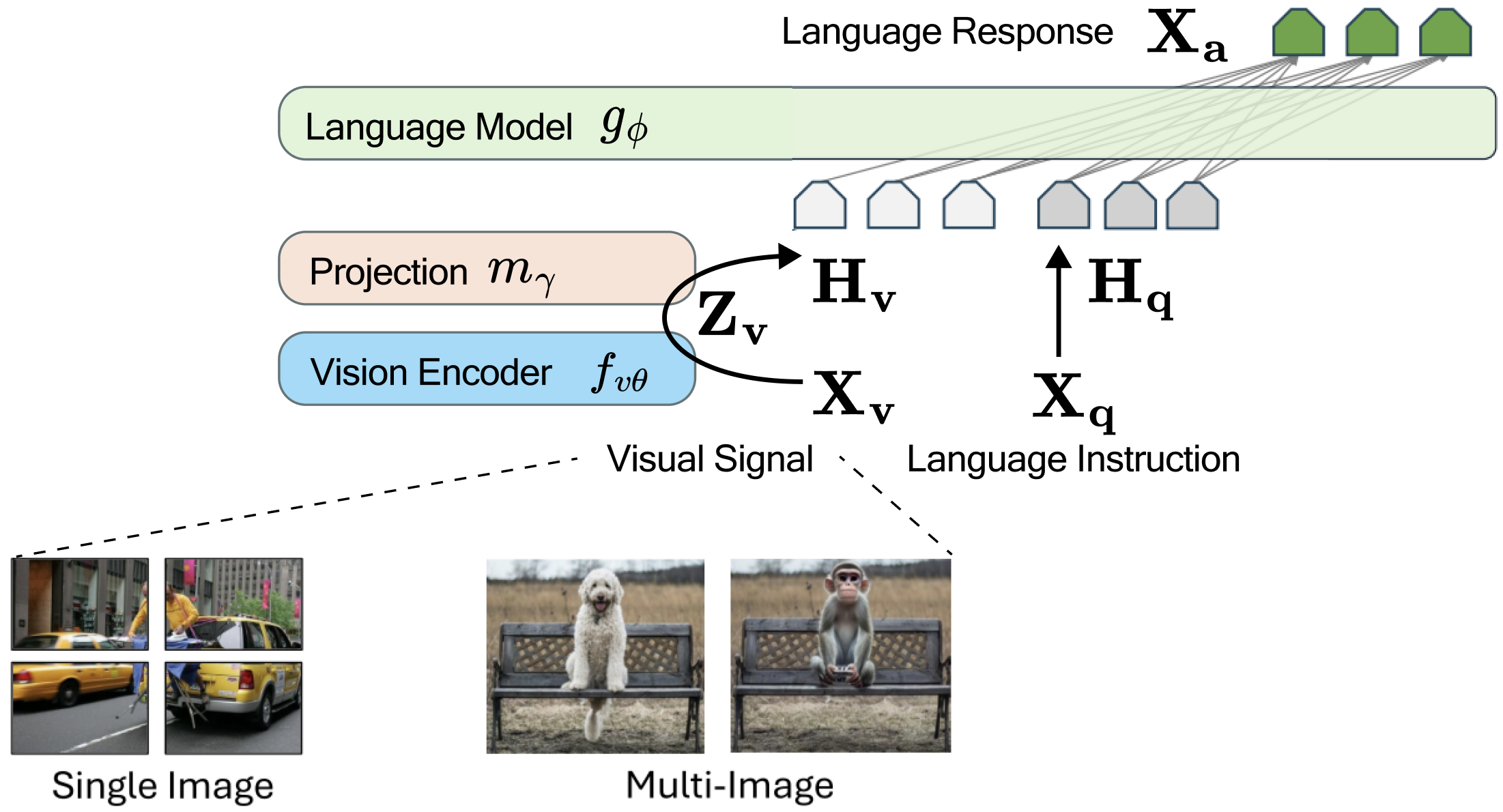
Demystifying Multimodal Learning:
Enabling Vision in Language ModelsA blogpost series on the nuts and bolts of Multimodal Learning
-
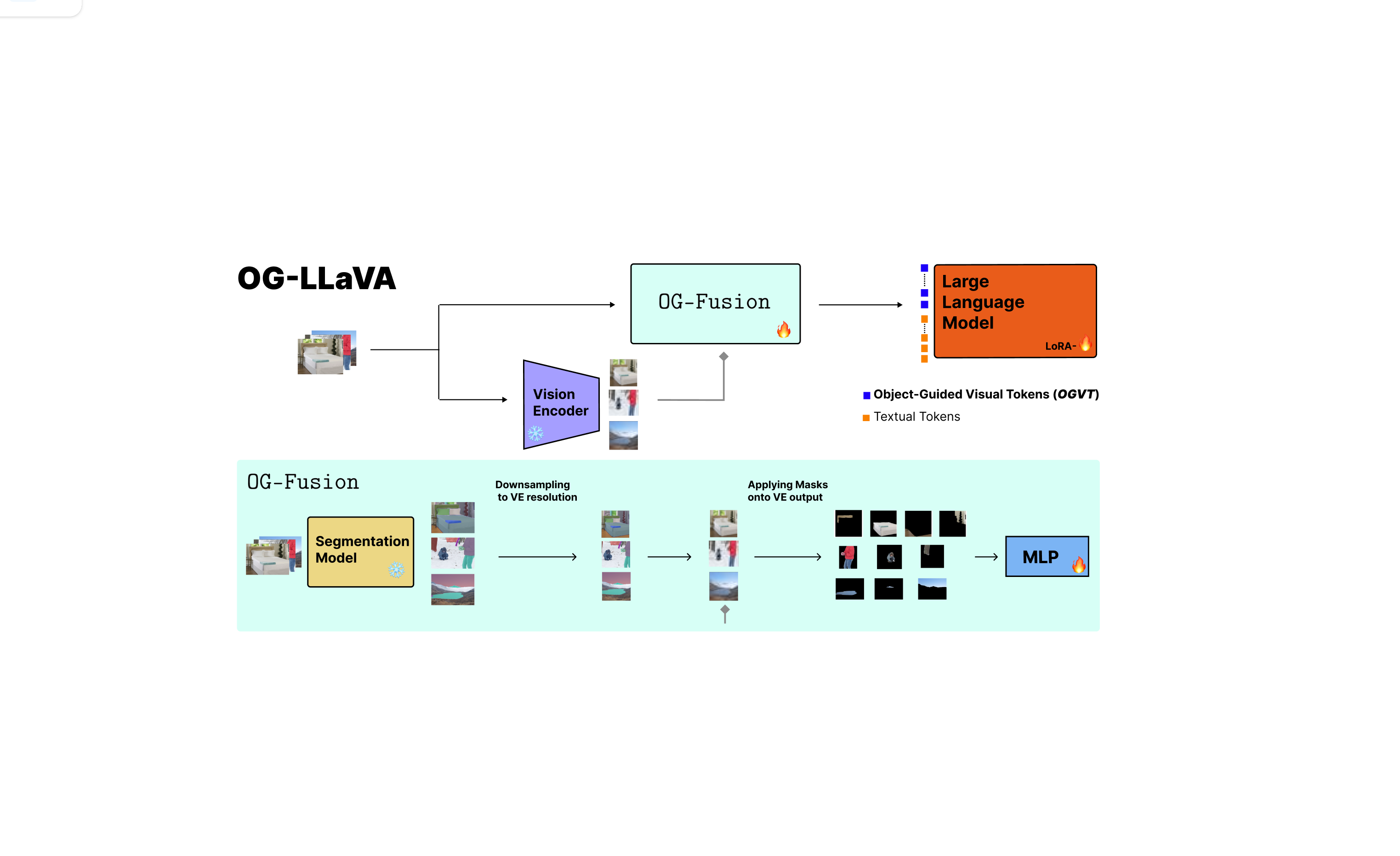
Object-Guided Visual Tokens: Eliciting Compositional Reasoning in Multimodal Language Models
Addressing MLLMs shortcomings in Compositional Reasoning through CLIP-Segmentation fusion
-
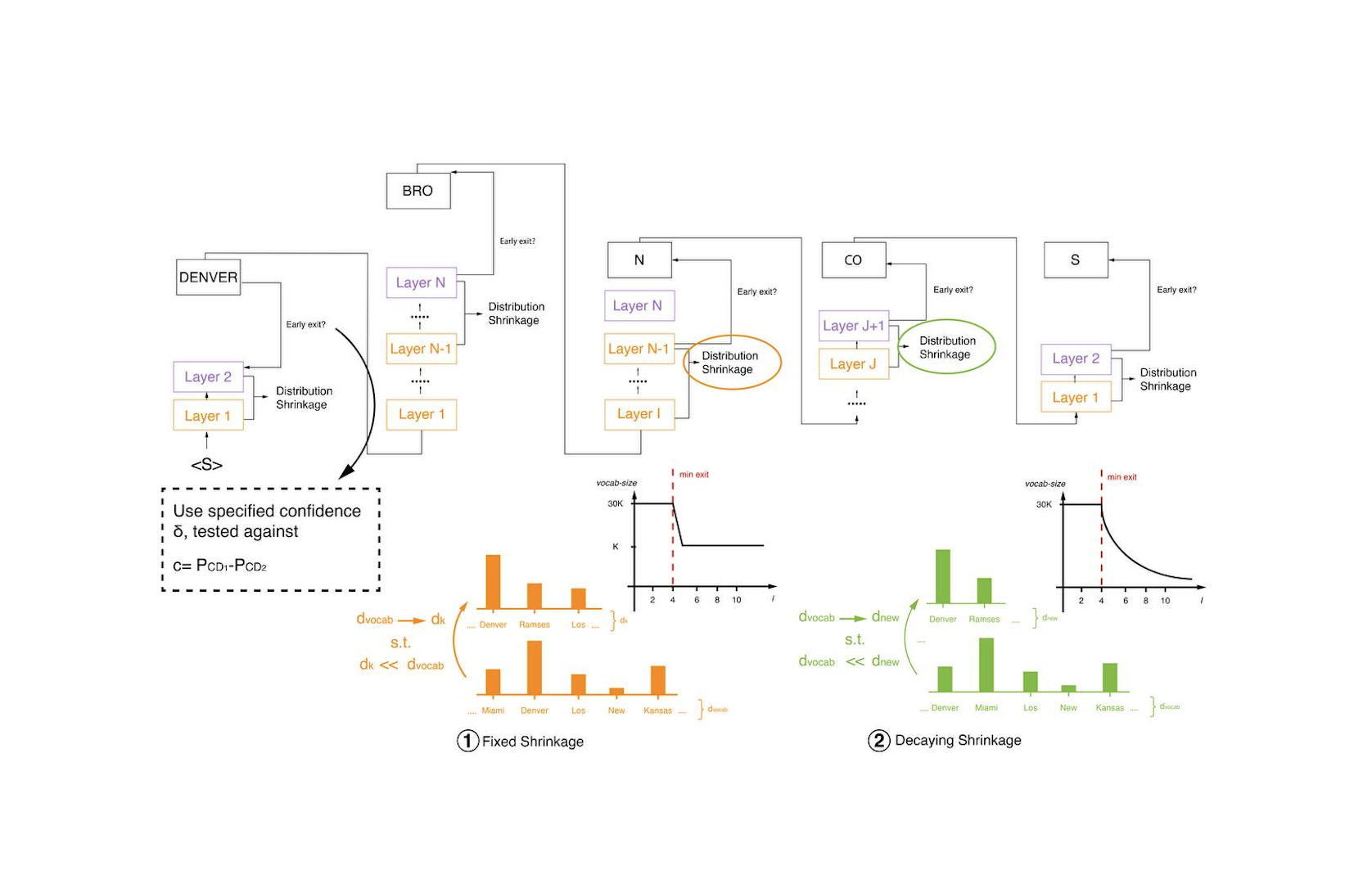
Optimizing Predictions: Vocabulary Reduction and Contrastive Decoding in LLMs
Efficiency-focused early exiting, vocabulary pruning, and contrastive decoding for LLM inference
-
Perception, Localization, Planning and Control on RAE Robots
Computer Vision for Autonomour Robots
